如今網絡已經成為多數人們生活中的一部分,不管遇到什麼問題都會在網絡上查找解決辦法,如果有好的方法我們可以將其步驟保存下來,但是最近有用戶在使用XP系統浏覽網頁的時候發現部分網站的內容不能復制,這是怎麼回事呢?
很多網站限制了用戶的復制,其實這麼做有的是為了版權,有的是為了讓用戶能夠在回頭以借此提高訪問量等,具體原因也說不清楚,但是碰到有用得上的文章又復制不下來,的確是很讓人著急,下面給大家介紹解決辦法。
第一招
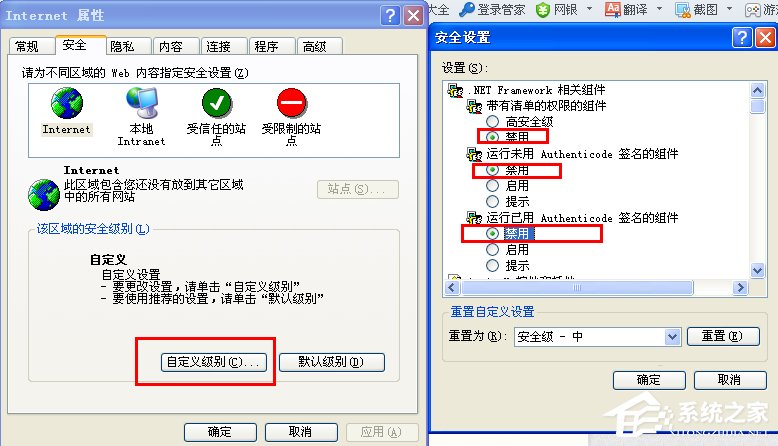
點擊浏覽器的“工具”—“internet選項”—“安全”—“自定義級別”,然後將腳本全部禁用,按F5刷新一下網頁。這時候你就會發現之前不能復制的內容,現在都沒有問題了!(提示:復制完想要的東西之後,記得把禁用的腳本解禁,否則會影響正常浏覽的)
第二招
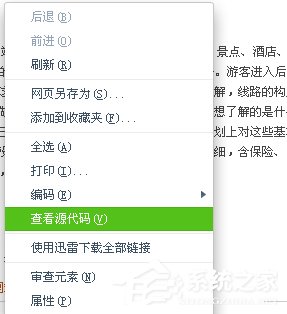
這招說其實是最簡單,但有時最麻煩的一招。直接右擊然後“查看源文件”,在源文件代碼中復制需要的文章。不過復制文章的時候會有很多用不著的符號和代碼,是有些麻煩。

第三招
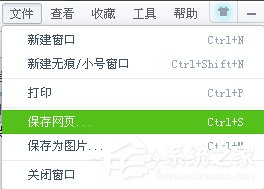
點擊浏覽器的“文件”菜單欄,選擇“保存網頁”然後點開保存的文件,下載下來想要的網頁,然後用word文本打開就可以了!
第四招
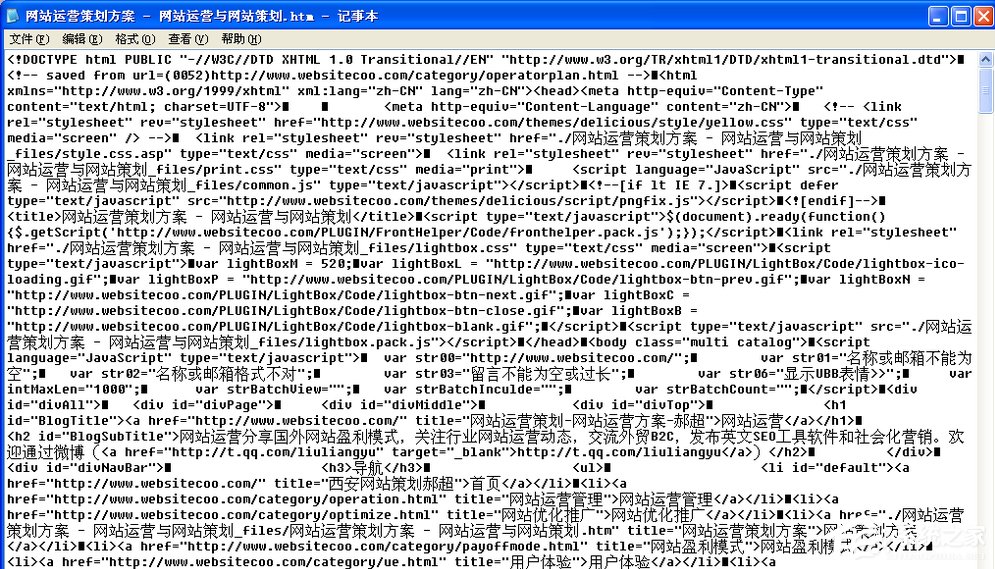
打開想要下載的網頁,然後把該網頁另存到電腦上面,接著用記事本打開的方法打開!在記事本中找到(onpaste= “reture flase”不准粘貼 oncopy=“reture flase;”不准復制 oncut=“reture flase;”不准剪切 onselectarst=“reture flase”不准選擇)這句語句或者類似的代碼,然後把這句代碼去掉,body模塊中的除外,然後保存記事本。接著雙擊打開剛才保存的記事本,這時候出現的文章就是可以復制的文章了。
以上便是解決網頁無法復制的方法,本文是以XP系統為例,當用戶使用別的系統碰到這個問題,同樣可以使用這個方法來解決。如今已經有越來越多的網站會用這個方法來保護版權,所以用戶掌握了這個方法還是很有用處的。