在對OneAPM的客戶做技術支持時,我們常常會看到很多客戶根本沒意識到的異常。在消除了這些異常之後,代碼運行速度與以前相比大幅提升。這讓我們產生一種猜測,就是在代碼裡面使用異 常會帶來顯著的性能開銷。因為異常是錯誤情況處理的重要組成部分,摒棄是不太可能的,所以我們需要衡量異常處理對於性能影響,我們可以通過一個實驗看看異常處理的對於性能的影響。
實驗
我的實驗基於一段隨機拋出異常的簡單代碼。從科學的角度,這並非完全准確的測量,同時我也並不了解HotSpot 編譯器會對運行中的代碼做何動作。但無論如何,這段代碼應該能夠讓我們了解一些基本情況。
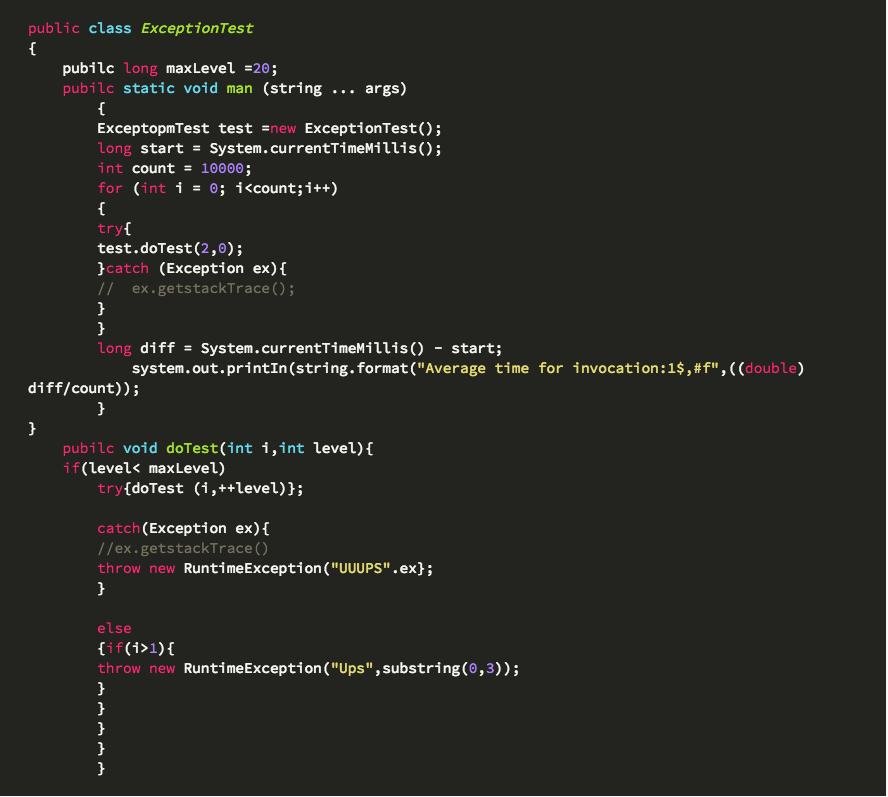
結果很有意思:拋出與捕獲異常的代價似乎極低。在我的例子裡,大約是每個異常 0.02 毫秒。除非你真的拋出太多異常(我們指的是 10 萬次或者更多),否則這一點基本都可忽略。 盡管這些結果顯示出異常處理本身並不影響代碼性能,但卻並未解決下面這個問題:異常對性能的巨大影響該由誰負責?
我明顯遺漏了什麼重要的問題。
重新想了一下,我意識到自己遺漏了異常處理的一個重要部分。我沒考慮到異常發生時你做了什麼。在多數情況下你很有可能不僅僅是捕獲異常!而問題就在 這裡:一般情況下,你會試圖對問題進行補充,並讓應用在最終用戶那裡仍能發揮功能。所以我遺漏的就是:“”為了處理異常而執行的補充代碼“”。按照補充代 碼的不同,性能損失可能會變得相當顯著。在某些情況下這可能意味著重試連接到服務器,在另一些情況下則可能意味著使用默認的回滾方案,而這種方案提供的解 決辦法肯定會帶來非常差勁的性能。對於我們在很多情況下看到的行為,這似乎給出了很好的解釋。
不過我卻不覺得分析到這裡已經萬事大吉,而是感到這裡還遺漏了別的什麼東西。
Stack trace
對此問題,我仍頗為好奇,為此監視了收集 strack trace 時情況性能有何變化。
經常發生的情況應該是這樣的:記下異常及其棧軌跡,嘗試找出問題到底在哪。
為此我修改了代碼,額外收集了異常的 strack trace 。這讓情況顯著改變。對異常的 strack trace 的收集,其性能影響要比單純捕獲並拋出異常高出10倍。因此盡管 strack trace 有助於理解哪裡發生了問題(有可能還有助於理解為何發生問題),但卻存在性能損失。 由於我們談論的並非一條 strack trace,所以此處的影響往往非常之大。 多數情況下,我們都要在多個層次上拋出並捕獲異常。 我們看一個簡單的例子: Web 服務客戶端連接到服務器。首先,Java 庫級別上存在一個連接失敗異常。此後會有框架級別上的客戶端失敗異常,再以後可能還會有應用層次上的業務邏輯調用失敗異常。到現在為止,總共要搜集三條 strack trace。 多數情況下,你都能從日志文件或者應用輸出中看到這些 strack trace,而寫入這些較長的strack trace 往往也會也帶來性能影響。
結論
首先因為存在性能影響而把異常棄之不用並非良策。異常有助於提供一種一致的方式來解決運行時問題,並且有助於寫出干淨的代碼。但我們應該對代碼中拋 出的異常數量進行跟蹤,它們可能導致顯著的性能影響。所以 OneAPM 默認要對所拋出的異常進行跟蹤——在很多情況下人們都會對代碼中發生的異常以及在解決這些異常時的性能損耗感到吃驚不已。 其次盡管使用異常很有裨益,您也應避免捕獲過多的 strack trace。異常應該是為異常的情況而設計的,使用時應該牢記這一原則。當然,萬一您不想遵從好的編程習慣,Java 語言就會讓您知道,那樣做可以讓您的程序運行得更快,從而鼓勵您去那樣做。