筆者使用的是基於虛擬機的Hadoop分布式安裝,由於關閉datanode和namenode的順序不恰當,所以經常會出現datanode加載失敗的情況。
本人的解決方法適用於首次已經成功啟動整個集群,但是由於不正常的操作造成第二次無法正常啟動。首次的啟動失敗可能原因有很多:可能是由於配置文件錯誤寫入造成的,或是由於ssh無密碼登陸配置錯誤造成。
而第二次的錯誤原因與首次啟動的有一些區別,排錯重點應該集中在程序在運行中的一些動態加載而生成的文件上,筆者要討論的是第二種情況:
大多原因就是因為hadoop的datanode的VERSION文件中的namespaceID與namenode中的VERSION文件中的namespaceID二者出現不一致的情況。而namespaceID的生成筆者推斷應該是在執行:hdfs namenode -format 這個命令的時候生成的。
解決步驟如下:
1,首先停掉namenode上相關的進程:切換到hadoop的/sbin目錄下:
sh stop-dfs.sh
sh stop-yarn.sh
2,切換到hadoop的相應/current目錄下將current下的所有文件清除。
3,將datanode與namenode的/current 下VERSION等相應文件文件清除後,回到namenode上,執行hsfs namenode -format命令,接著切換到namenode的hadoop的/sbin目錄下:
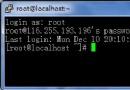
執行sh start-dfs.sh
sh start-yarn.sh
(舊版本的mapre 被新版本的yarn所替代,命令上多少有些不同)
既可以看到相應的節點成功加載。
相應的思想就是,當出錯時,清除掉一切干擾思路的文件,然後整理思緒,重新開始,這樣要遠比在原地徘徊要好。
(由於我們在配置文件中指明的文件夾只有 hdfs tmp log,所以其余的文件也好文件夾也好都是動態執行腳本生成創建的,刪除之後只要hadoop整個系統可以工作就會生成,即便錯刪,VM的 snapshot 也會拯救這個世界。)