簡介: 本文就 CJKTTY 補丁如何讓 linux 虛擬終端顯示漢字的原理進行了討論,為此介紹了 Linux 虛擬終端和其依賴的硬件的工作原理。過程中我們分析了 Linux 字符終端的不足之處,並向讀者介紹前沿的 Wayland system compositor 是什麼以及為什麼 需要它。
CJKTTY 補丁是什麼,為什麼我寫了它
當你不使用 X 的時候,打開電腦,你就在使用虛擬終端。這麼多年來它工作的很好,直到它來到了中國。包含中文字符的文件名無法正確顯示,中文文檔無法閱讀。當然可以使用 X , 但是我為什麼不能讓終端也能顯示漢字呢?如果在 X 下我能讓屏幕顯示漢字,終端下一定也能。為此我開始了 internet 上的搜尋。 我找到了 fbterm,這是個可以利用 /dev/fb0 實現的終端模擬器,和 XTERM 一樣,只不過 XTERM 利用的 X 繪制文字,而 fbterm 直接寫入 /dev/fb0。
/dev/fb0 是什麼?
幀緩沖區設備。幀緩沖區是一塊存儲區域(內存或者顯存或者其他的輸出設備的存儲空間),內核將其抽象為一個設備。通過訪問該設備就能訪問幀緩沖區。幀緩沖區的內容既是屏幕映像。由輸出設備不停的掃描幀緩沖區生成顯示設備的控制信號。
然而我似乎總是忘記登錄後開啟 fbterm,對我來說,等看到亂碼的時候突然想起沒有開啟 fbterm 並不是那麼愉快的經歷。這只是其中一個缺點。fbterm 占用了幀緩沖區設備,導致 w3m 這類使用幀緩存繪制圖像的終端 www 浏覽器不能正常工作。許多依賴幀緩沖區設備的終端程序都不能被 fbterm 良好的兼容。 於是我繼續尋找,找到了 youbest 寫的中文補丁。 我有個喜歡使用最新內核的習慣,當內核升級導致 youbest 的補丁再也不能使用的時候,我開始到 youbest 發布補丁的頁面留言,希望 youbest 百忙中能修改一下他的補丁。
Youbest 似乎很忙,在新內核的誘惑下,我決定自己在修改。那個時候我才真正的開始看內核的代碼。終於了解了虛擬終端的工作原理後,我開始修改內核。由於內核內部結 構變動導致 youbest 的補丁無法應用,我幾乎是從頭開始了開發而不是簡單的將無法應用的部分進行修整。唯一得到保留的就是 youbest 補丁中的點陣字庫。我將其命名為 CJKTTY , 取能顯示 CJK 的 TTY 之意。
從那裡獲得中文顯示補丁呢?
我將補丁托管在了 http://repo.or.cz/w/linux-2.6/cjktty.git,依據你使用的內核版本,簽出內核版本 -utf8 分支就可以。
控制台是如何顯示文字呢?
那麼,為了能在控制台下顯示出漢字到底需要做什麼樣的修改麼?在開始前,我想先介紹一些名字,並介紹一些控制台在硬件上是如何進行文字顯示的。 首先我解釋一下幾個名詞,知道的人可以到這裡開始閱讀。
UNICODE
為每一個字符分配全球唯一的一個數字,但是並沒有規定這個數字的表示方法。數字的表示方法由 UTF 規范規定。UTF-16 使用 2 個字節表示一個 UNICODE 數字,但是對於 >=216的數字使用 4 字節來表達。UTF-8 則對於 <127 的數字采取單字節表示,大於 127 的數字要根據其大小選擇 2~6 個字節進行表示。UNICODE 在程序內部則簡單的使用 unsigned long 即可表示一個字符。
GLYPH
GLYPH 指的是字體裡的字形。字符總是要在特定的字體下表示的,該表示就是字形。比如一個只包含 26 個大小寫字母的字體,只包含了 52 個字形,如果該字體是先大寫後小寫排列的,那麼數字 0 就表示字形 'A' , 數字 1 就表示字形 'B'。UNICODE 或者 ASCII 到 GLYPH 的映射是由一個稱作 CMAP 的映射表做的。如果字體裡字符就是按照 UNICODE 排列的,則其 CMAP 就是 UNICODE CMAP。同理也有 ASCII CMAP。 VGA 自帶字體沒有提供 CMAP,操作系統假定它的 CMAP 是 ASCII CMAP。事實上也是如此。
TTY
內核為終端提供的接口,對應用程序而言就是 TTY 設備。通常是使用 stdin stdout 來訪問。TTY 提供各種 IOCTL 用來設置終端的模式。TTY 也提供了用戶控制程序的方法,比如 Ctrl-C 終止當前程序。 TTY 可以是顯示器 + 鍵盤構成的控制台,也可以是串口(可以通過貓鏈接到電話線上),可以通過 pts 模擬。XTERM 即利用 pts 為裡面運行的程序提供的模擬的終端 , 對應的設備文件 /dev/pts/* 由模擬終端程序動態創建。
控制台 (CONSOLE)
控制台特指由顯示器 + 鍵盤構成的終端。其中顯示器由顯卡控制,而且當前 VGA 兼容顯卡有兩種模式,文字模式和圖形模式。Linux 即可以使用文字模式也可以使用圖形模式。
控制台對於程序是無法訪問的,程序只能通過虛擬終端使用控制台
虛擬終端 (VT)
如果你的電腦只有一個終端,那將是多麼乏味。一個需要長時間執行的任務就能導致你什麼也做不了,Linux 的多任務機制的好處蕩然無存。所以,你需要更多的終端。Linux 內核使用復用機制,將一個控制台復用為多個終端 (63 個,/dev/tty1 到 dev/tty63)。 按鍵 Alt+F1-F12 ( 如果當前在 X 中,需要再按下 Ctrl 鍵 ) 能在 12 個終端中進行切換。事實上你擁有 63 個終端,鍵盤只能切換其中的 12 個,其他的終端你可以通過 chvt 命令進行切換。
當前擁有顯示器和鍵盤的虛擬終端被稱為活動終端或者當前終端。
TTY、控制台和虛擬終端有啥區別和聯系?
當你按下 Ctrl-C 的時候,當前執行的程序會被終止。因為 Linux 發送了 SIGTERM 信號給此終端的前台程序。該信號並不是由 Shell 產生,而是內核。不論是在虛擬終端下,還是在 X 裡的終端模擬器裡,這個功能都是一樣的。終端的一大功能就是進行任務控制,另一個功能是輸入輸出。輸入輸出模式下,還可以選擇行編輯模式,回顯模式,設置 終端速率等等。不管你使用的是何種終端,這些功能都是存在的,因為他們都是一個類型的設備。內核將他們抽象為 TTY 設備。也就是說,應用程序都是在和 TTY 這個抽象層打交道,而不是和具體的設備打交道。 能作為 TTY 的設備除了控制台外,還有串口。將兩台電腦的串口連接起來,其中一台電腦為串口打開登錄程序(執行 /sbin/agetty ttyS0 38400),另一台就能通過可以進行串口通信的程序 ( 比如 putty、minicom) 登錄對方。 控制台可以作為 TTY 設備,但是一台電腦一般只有一個屏幕,也就使用一個控制台,所以 Linux 在控制台和 TTY 之間加了一層虛擬終端。由虛擬終端將控制台復用,這樣就可以使用多個終端而不是只有一個了。多個虛擬終端設備合作使用一個控制台。 除了串口和虛擬終端,這些都是在內核實現的 TTY 設備,內核還提供了一個叫 PTY 的為終端設備,XTERM 之類的程序利用 PTY 提供的功能可以在程序裡實現 TTY 的功能。 那麼,虛擬終端就是利用控制台復用出了多個 TTY 。TTY 邏輯由 TTY 子系統完成,復用邏輯由虛擬終端實現,而具體的顯示則交給控制台完成。如果說這是一個觀察者模型的話,控制台就是觀察者,它將虛擬終端的內容呈現到屏幕 上。 在 Linux 下,控制台分文字模式控制台(vgacon)和圖形模式控制台 (fbcon)。
文字模式控制台 (VGA 文字模式 )
文字模式控制台使用 VGA 兼容顯卡的文字模式實現 VGA 兼容顯卡初始化時默認就處於文字模式,能顯示 80x25 個字符。
在文字模式下,顯卡雖然輸出給顯示器的是圖像,但是顯卡提供給內核的卻只能顯示文字功能。要顯示一個字符,內核將要顯示的字符的代碼和屬性寫入字符緩沖區相應地址即可。緩沖區如下面所示:
圖 1. 緩沖區
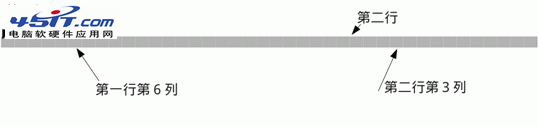
表 1. 每個字符的格式
6
5
4
3
2
1
0
7
6
5
4
3
2
1
0
閃爍
背景色
前景色
GLYPH
VGA 顯卡處於文字模式時,物理地址 0xB8000 即文字緩沖區起始地址,大小由其文字模式決定,最大 32KB 。VGA 顯卡內建字符發生器,不斷的掃描字符緩沖區並將文字轉換為圖形驅動顯示器顯示。其 GLYPH 即為字符的 ASCII 碼。
字符發生器和字體
字符發生器內建一個或者多個位圖字體。使用何種字體取決於設置的文字模式代碼。Linux 默認使用 80x25 字符 16 色模式 , 每字符 8x16 點陣。 字符發生器的字體包含 256 個字形。字符發生器裡的文字和字符的對應關系在 DOS 系統下被稱為代碼頁。顯卡自帶的被稱為 OEM 代碼頁。
字符發生器的字體可以修改。DOS 下通過修改代碼頁實現。Linux 下可以使用 setfont。
因為這一歷史原因,VGA 的文字模式最多同屏出現 256 種不同的字符。對於只有 26 個字母的拉丁文字綽綽有余,但是卻無法滿足擁有上萬字符的中文。 文字模式控制台由 vgacon (drivers/video/console/vgacon.c)實現。 VGA 還有不常使用的單色文字模式,起始地址為 0xB0000 。並且字符格式也有所不同,這裡不再介紹。
圖形模式控制台
圖形模式控制台直接操作幀緩沖區顯示文字。幀緩沖區是一塊存儲區域(通常是在顯存中),其內容就是顯示在屏幕上的圖像。顯卡直接將其內容轉化為顯示器控制信號。對於程序而言,幀緩沖區就是屏幕。
圖像模式控制台使用幀緩沖區作為屏幕輸出,要想使用圖像模式控制台,必須加載幀緩沖區驅動並有相應的硬件。
不同的顯示設備通常使用不同的幀緩沖區驅動,對於 VGA 兼容顯卡,除了能使用針對顯卡寫的幀緩沖區驅動 ( 如果有的話 ),還可以使用通用的 VESA 驅動。 VESA 驅動利用 VGA 兼容的顯卡的 BIOS 將顯卡轉入 VGA 圖形模式並設置期望的緩沖區模式,由顯示模式內核參數 vga= 給出。 VGA 圖形模式下,幀緩沖區的起始地址為 0xA0000 ,最大 64KB 大小。像素格式看顯示色深。典型的 256 色模式下每像素一個字節。 如果 BIOS 支持 VBE 擴展,能設置更大的分辨率和色彩深度,幀緩沖區大小也會超過 64KB,因而起始地址也不再是 0xA0000,具體細節請參考 維基百科. 幀緩存模式下,Linux 內核將需要顯示的字符首先轉換為位圖,然後將位圖字體寫入幀緩存即可變呈現於屏幕。 也就是說,圖形模式下,由內核來承擔字符發生器的工作。理論上來說,這個內核自帶的字符發生器將能支持顯示多於 255 種字符。但是我將在後面告訴讀者,因為歷史原因,內核實現的字符發生器和 VGA 的字符發生器有著一樣的缺點。 圖形控制台由 fbcon(drivers/video/console/fbcon.c)實現。圖形控制台由於需要生成位圖字形,需要帶上位圖字體,編譯內核的時候至 少需要選擇一個字體。位圖字體在內核是一個大數組,不同的字體 ( drivers/video/console/font_* ) 存儲在各自的數組中。
為何圖形模式控制台也不能顯示漢字
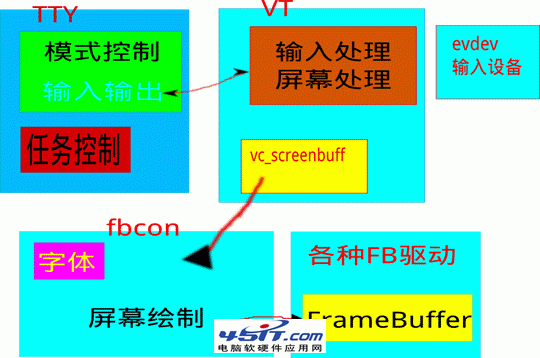
要解釋圖形模式控制台為何不能顯示漢字,首先我們來了解一下虛擬終端是怎麼管理屏幕上的文字顯示的。 虛擬終端的實現在 drivers/tty/vt/vt.c 。代表虛擬終端的數據是 struct vc。
struct vc{
struct vc_data;
struct work_struct;
};
故而 struct vc_data 才是我們要的虛擬終端的定義。我們先來看看 struct vc_data 到底定義了什麼東西吧。
struct vc_data 的定義在 include/linux/console_struct.h, 定義摘錄如下,爲了不延長篇幅,有省略的部分:
struct vc_data {
struct tty_port port; /* Upper level data */
unsigned short vc_num; /* Console number */
unsigned int vc_cols; /* [#] Console size */
unsigned int vc_rows;
省略 ...
const struct consw *vc_sw;
unsigned short *vc_screenbuf; /* In-memory character/attribute buffer */
unsigned int vc_screenbuf_size;
省略 ...
};
其中 vc_screenbuf 存儲了虛擬終端要顯示在屏幕上的文字。 const struct consw *vc_sw 指向控制台驅動提供的函數。虛擬終端利用裡面的函數指針調用相應的操作,比如重繪屏幕,繪制一個字符等等。這些操作由 vgacon 和 fbcon 等控制台驅動實現。 當你切換終端的時候,實際上就是把當前終端設置為你要切換過去的終端,並且重新繪制當前終端 vc_data->vc_screenbuf 存儲的內容。 當你從鍵盤輸入命令或者程序運行過程中要輸出內容的時候,虛擬終端首先將輸出的字符進行編碼轉化,轉化為對於字符的 GLYPH 代碼,並且將 GLYPH 和當前字符屬性結合,最後將合成結果寫入當前光標所處的位置。內核中實際的算法要復雜的多,還牽涉到中斷,但是為了簡單快遞的把我們關心的部分的核心表達 出來,我使用一下偽代碼表示不那麼嚴謹的過程。希望了解全部的讀者可以自行查看內核相關的代碼,主要代碼在 drivers/tty/vt.c 的 do_con_write() 中。
清單 1. 偽代碼
vc_write(vc_data * vc, const char * string, int count){
for( ; count ; ){
/* 和當前編碼有關,如果是 utf8 就以 utf8 方式解碼不是 utf8 就按照 擴展的 ASCII 方式,也就是一個字節就是一個字母。*/
int glyph = next_char(vc->utf,&string,&count);
int c = vc_build_attribute(vc)|(vc_glyph_mask& glyph);
// 把當前設置的前景色背景色等屬性結合 ,glyph 不能超過描述它的位段 ;
vc->vc_screenbuf[vc->vc_pos] = c; // 寫入當前位置
update_pos(); // 更新當前光標位置
}
notify_redraw(vc); // 調用 cosole 這個觀察者重會屏幕
}
你也許想知道 vc_screenbuf 指向的緩沖區的格式到底是怎樣的,現在也可以回答 前面提 到過的為何圖像控制台依然不能支持漢字顯示的問題了:vc_screenbuf 的格式就是 VGA 文字模式時顯卡所使用的文字緩沖區格式。上述偽代碼中的 vc_glyph_mask 就是 0xFF, 也就是 glyph 被截斷只能 8 比特長度。 打從一開始,fbcon 就是按照 VGA 字符發生器設計的。因為當 vc_screenbuf 的格式和 VGA 字符緩沖區的格式一致的時候,切換終端就可以只需要 memcpy ——快速的拷貝到 VGA 字符緩沖區就能實現“重繪”當前終端。現在看來這種做法局限性非常大,但是單年 PC 性能還不夠強大的時候,能做到快速的重繪是非常重要的。 重繪例程中,notify_redraw(vc) 用偽代碼表示為
清單 2. notify_redraw(vc) 偽代碼
notify_redraw(vc_data * vc){
for(int rows = 0 ; rows < vc->rows ; rows ++){
unsigned short * current_line = &
vc->vc_screen_buf [vc_size_row * rows + vc->vc_visible_origin ] ;
// 在屏幕的第 row 行第 0 列繪制一行 current_line 指向的內容共 vc->cols 個字符。
vc->vc_sw->con_puts(vc,current_line,vc->cols,0,rows);
}
}
vc_sw 是個由控制台代碼提供的指針,類型為 structconsw * , 控制台驅動的初始化部分會使用 vt_unbind() 將自己綁定為虛擬終端使用的控制台,傳入的信息中就包括 vc_sw。 在 vgacon 中 vc_sw->con_puts 事實上就是將要顯示的內容簡單的拷貝到 VGA 的字符緩沖區。對於 fbcon 而言則要復雜的多。 fbcon 提供的 con_puts 將 glyph 作為一個下標在 vc->vc_font 中找到對應的位圖數據,然後拷貝到幀緩沖區。 TTY-> 虛擬終端 -> 控制台 -> 屏幕的路徑用一幅圖片表達為:
圖 2. 路徑
圖形模式控制台的改造
fbcon 將 glyph 作為下標到 vc_font 中獲取位圖數據,而 glyph 要麼是一個 unicode (vc->utf=1 的時候,當然是被截斷到 8 個比特)要麼就是擴展的 ASCII 代碼。 由於擴展 ASCII 只有 8 個比特位表示一個字符,所以只能請出 unicode 作為中文的數字表示。要想控制台能支持漢字顯示,需要解決 3 個問題:
包含更多的字符,不只是 255 個,並提供代碼繪制雙倍寬度的中文字形,字體中的字符按照 UNICODE 排列,這樣 glyph 就是字符的 UNICODE 編碼。修改虛擬控制台
一開始,我的打算是 vc_screenbuf 修改為 unsigned long long* 類型,32bit 給字符屬性,分別表示 16bit 終端前景色和背景色。glyph 則擁有 31bit 的空間 , 因為漢字的寬度為雙倍的英文字母 ,其中 1 bit 用來表示雙字符寬度。比如 '我' 會表達為 兩個 '我',第二個'我'的最高位為 1:繪制任何字形的時候,只繪制字形的左半部分;如果發現最高位為 1 則繪制字體位圖中的右半部分。這樣同樣的繪制代碼可以適應英文字母和漢字。 寫入 vc_screenbuf 的時候, 如果是雙倍寬度的字符,需要同時寫入兩份,第二份的最高位置 1 就可以。 但是 vc_screenbuf 的格式已經被到處假定為每字符兩個字節。如此修改導致牽一發動全身。許多艱澀難懂的代碼都依賴 vc_screenbuf 是 每字符兩個字節的設定,直接修改定義後,光是編譯器能直接檢測出來的就有百余個地方需要修改,還有更多的邏輯並不能被編譯器檢測出來。 如此修改的後果就是會出現許多隱晦的錯誤,非常難於調式。掙扎後,為最終選擇了另一條道路 :
為漢字重新分配一塊 vc_unicode_screenbuf
vc_unicode_screenbuf 緊挨著 vc_screenbuf , 事實上 vc_screenbuf 在分配空間的時候,多分配了一倍的空間,多分配的空間充作 vc_unicode_screenbuf,因此 struct vc_data 裡並沒有添加 vc_unicode_screenbuf 成員。 vc_unicode_screenbuf 同樣為每字符 2 個字節,並不包含字符屬性,所以 2 個字節如數用來保存 glyph。vc_screenbuf 格式未變,所以 vgacon 不需要修改,這就減少了大量的工作量。 向 vc_screenbuf 寫入字符的時候,同時寫入一份到 vc_unicode_screenbuf 。如果是漢字,由於其 glyph 大於 254 , 所以 vc_screenbuf 的那兩個字符 ( 漢字雙倍寬度 ) 實際寫入的是 0xff 和 0xfe ( 故而上文提到是 glyph 大於 254 的字符 ,0xfe 被保留它用了 )。0xff 表示該字符的 glyph 要到 vc_unicode_screenbuf 提取,然後繪制左半部分;0xfe 表示該字符的 glyph 要到 vc_unicode_screenbuf 提取,然後繪制右半部分。對於 glyph 大於 254 但是又不是雙倍寬度的字符,就不需要 0xfe 作陪了。 比如屏幕上顯示的文字是黑底白字的 “牛 B” , vc_screenbuf 的內容就是 “0x00ff, 0x0ffe, 0x0f42 ” , vc_unicode_screenbuf 的內容則是 “牛 , 牛 ,b” 。這是因為一個漢字為兩倍的英文字母寬度。在屏幕文字緩沖區上也必須占用兩個字符的位置。並且必須有一種機制能知道應該繪制左半部分和右半部分,我使用的 就是 0xff 和 0xfe。
修改圖形控制台繪制代碼
要修改的地方只有 3 個。
字符繪制代碼的修改比較繁瑣,代碼分布在 drivers/video/console/ 下的多個文件中。fbcon_putc(s) 由由 vc->vc_sw->con_putc(s) 調用, fbcon_putc(s) 轉而調用分散於 drivers/video/console/ 的多個 puts 實現。因為終端要支持 console_rotate , decoration , timing , 故而每種模式下的繪制實現都是不同的。 我拿 drivers/video/console/bitblt.c 最常用的不傾斜、不加裝飾等的終端模式為例來講解繪圖部分的修改。 由於中文字體為 16x16 點陣,是對齊的字體,故而其繪制代碼為 bit_putcs_aligned() 原先的代碼以 glyph 為下標到 vc->vc_font->data 獲得字體數據,然後調用 fb_pad_aligned_buffer 執行塊拷貝操作。 我的修改很簡單,原來獲得字體數據的代碼修改後放入 font_bits() 輔助函數。 在 font_bits 裡,要判斷 glyph 是否為 0xff 或者 0xfe, 如果不是,使用 glyph 為下標獲得字體的左半部分後並返回。 如果是,則從 vc_unicode_screenbuf 獲得真正的 glyph 數值,然後再依據現有的 glyph 是 0xff 還是 0xfe 去獲得字體的右半部分還是左半部分返回。font_bits 獲得字體數據後執行 fb_pad_aligned_buffer 塊拷貝。 需要修改的地方還有 drivers/video/console/fbcon_ccw.c fbcon_cw.c fbcon_ub.c 。依原理進行修改即可。
虛擬終端的不足之處
雖然費盡心機添加了中文支持,那只是一個 workaround , 並不能算真正的支持。要真正的支持必須徹底重寫虛擬終端和控制台。而要支持中文,就需要更進一步,全面支持 UNICODE , 包括支持從右向左的書寫習慣。 在內核裡實現一個全面支持 UNICODE 的控制台並不是一件容易的事情,何況內核的政策也不允許將如此龐大的字庫裝入內核。於是乎,這裡出現了死胡同。KMS 和 Wayland 的出現讓這死胡同似乎有了個完美的解。
KMS:
KMS 是內核模式設置 (Kernel Mode Setting)的縮寫。傳統上內核使用 VGA 模式,該模式由 BIOS 或者 bootloader 設置。如果啟動 Xorg, 則 Xorg 使用自己的驅動將顯示模式進行切換。這導致內核並不知道顯卡的當前工作狀態,虛擬終端切換必須依賴 X 進行。X 鎖死會導致整個終端被鎖定無法進行切換。待機、休眠等功能必須依靠 X 和內核雙方進行深度合作才能實現。讓一個用戶程序搞垮內核是不可以接受的,故有 KMS , 希望通過把模式設置代碼移入內核,減少內核對 X 的依賴。
如果不使用 X , KMS 對於控制台來說就是支持了顯示器的本地本分辨率。KMS 優勢並不顯著。但是 Wayland 的介入使事情發生了變化。 有關於 Wayland 的詳細文檔請參考 freedesktop.org 上的 項目首頁。Wayland 並不只是對桌面帶來了福音,同時也為控制台帶來了福音,因為 Wayland 可以代替內核自身的虛擬終端和控制台實現。 而這個代替者就是 System Compositor
System Compositor?
System Compositor 是一個 wayland compositor,只是運行於系統全局范圍。
為了懶人我這裡稍微講解一下 wayland compositor 吧。 Wayland 不同於 X , 在 wayland 的世界裡,只有 compositor 和 client。Client 利用各種 API (wayland 給出的示例使用的是 OpenGL ES, 但其實 wayland 並不限制使用的繪圖 API 類型 ) 進行窗口繪圖,然後將窗口的繪制結果直接提交給 compositor 合成到屏幕上。這樣 wayland 本身就不包含繪圖 API 而大大簡化了 wayland 的設計。Wayland compositor 可以同 X 一樣操作顯卡向屏幕輸出合成後的結果,也可以作為另一個 wayland compositor 的 client。
對於多賬戶同時登錄的實現,固然可以讓每一個本地 GUI 會話開啟一個 wayland compositor,但是存在更好的辦法就是固定開啟一個 system compositor。而讓所有用戶會話的 wayland compositor 再作為 system compositor 的 client. 藉由 system compositor 的合成效果,進行快速用戶切換也可以進行一些視覺效果。而且 Xorg 本身也已經支持作為 wayland client 運行,這樣可以使用傳統的 X 提供桌面,而讓 wayland system compositor 實現終端切換。 這還有一個好處,只有 wayland system compositor 是以 root 運行的,而用戶會話的 compositor 或 X 就不必以 root 權限運行。 因為 Wayland 非常輕量,所以 system compositor 可以作為系統級服務常駐內存運行。而因為有了 system compositor , 內核也不再需要實現虛擬終端了:只需要實現終端模擬器作為 system compositor 的 client 。由於是在用戶空間實現的,所有可以加入 UNICODE,矢量字體,國際化的書寫習慣等等的支持,再也不用受限於內核啦。 Wayland 還是一個非常年輕的項目,Wayland system compositor 目前還只是設想中的概念,需要更多的人關注參與。筆者相信不久的將來 wayland 一定能大有作為。
寫在最後
本篇簡要介紹了 Linux 虛擬終端的工作原理和依賴的硬件細節實現,然後使用了不太優雅的辦法讓虛擬終端在幀緩存模式下實現漢字的顯示。讓大家對虛擬終端有了一點點更多的了解,希 望本文能對想了解 Linux 的人有所幫助。也再次感謝 IBM DevelopWorks, 它讓我有機會把自己的知識共享給更多的人知道。