grep命令簡介:
在ex編輯器(我沒用過)中,啟動ex編輯器後要查找某個字符串時,在ex的命令提示符後鍵入:
:/pattern/p
:/g/pattern/p
grep這個名字就由來如此。其中p的含義是print,而當g出現在pattern前面的時候,其含義是“文件中所有行”,或“執行全局替換”。
被查找的模式稱作正則表達式(regular expression)因此,把pattern換成RE,於是就成了g/RE/p,grep。
grep命令語法:
前面的名字由來部分已經明確告訴我們,grep的作用是在一個或多個文件中查找茉個字符模式。egrep和fgrep都只是grep的變體,這裡我們不做介紹。看一下grep的語法結構。
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <sys/wait.h>
int main(int argc, char *argv[])
{
int pfd[2];
pid_t cpid;
char buf;
if(argc != 2)
{
fprintf(stderr,"Usage: %s <string>\n",argv[0]);
exit(0);
}
if (pipe(pfd) == -1)
{
perror("pipe");
exit(EXIT_FAILURE);
}
cpid = fork();
if (cpid == -1)
{
perror("fork");
exit(EXIT_FAILURE);
}
if (cpid == 0)
{
close(pfd[1]); /* Close unused write end */
while (read(pfd[0], &buf, 1) > 0)
write(STDOUT_FILENO, &buf, 1);
write(STDOUT_FILENO, "\n", 1);
close(pfd[0]);
exit(EXIT_SUCCESS);
}
else
{
close(pfd[0]); /* Close unused read end */
write(pfd[1], argv[1], strlen(argv[1]));
close(pfd[1]); /* Reader will see EOF */
wait(NULL); /* Wait for child */
exit(EXIT_SUCCESS);
}
}
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <sys/wait.h>
int main(int argc, char *argv[])
{
int pfd[2];
pid_t cpid;
char buf;
if(argc != 2)
{
fprintf(stderr,"Usage: %s <string>\n",argv[0]);
exit(0);
}
if (pipe(pfd) == -1)
{
perror("pipe");
exit(EXIT_FAILURE);
}
cpid = fork();
if (cpid == -1)
{
perror("fork");
exit(EXIT_FAILURE);
}
if (cpid == 0)
{
close(pfd[1]); /* Close unused write end */
while (read(pfd[0], &buf, 1) > 0)
write(STDOUT_FILENO, &buf, 1);
write(STDOUT_FILENO, "\n", 1);
close(pfd[0]);
exit(EXIT_SUCCESS);
}
else
{
close(pfd[0]); /* Close unused read end */
write(pfd[1], argv[1], strlen(argv[1]));
close(pfd[1]); /* Reader will see EOF */
wait(NULL); /* Wait for child */
exit(EXIT_SUCCESS);
}
}
grep使用的正則表達式元字符:
正則表達式中的元字符,我之前在javascript的日志中詳細介紹過。這裡不再解釋何為正則表達式,只讓大家來看一下在grep中使用的正則表達式元字符。
元字符 |
功能 |
示例 |
匹配對象 |
^
行首定位符
‘^simaopig%’
匹配所有以simaopig開頭的行
$
行尾定位符
‘simaopig$’
匹配所有以simaopig結尾的行
.
匹配任意一個字符
‘s.m’
匹配包含一個s字符,後面跟一個字符(隨意),再跟一個m的行
*
匹配0或多個前一字符
‘s*m’
匹配包含零個或多個s字符,後面跟有一個m字符的行
[]
匹配一組字符中的任意一個
‘[Ss]imaopig’
匹配simaopig,或者Simaopig
[^]
匹配不在指定字符組內的字符
‘[^a-z]imaopig’
匹配不包含在a-z之間的字符後跟著imaopig的行,即所有aimaopig-zimaopig的行都不包含(有點繞)
\<
詞首定位符
‘\<simaopig’
匹配以simaopig為開頭的詞的行,simaopigabcd也是可以的
\>
詞尾定位符
‘simaopig\>’
匹配以simaopig為結尾的詞的行,abcdsimaopig也是可以的
..
標記匹配的字符
‘
simaopig 's blog’
標記寄存器裡的一段字符,該寄存器被記作1號寄存器。以後引用這段字符時,可以使用\1來重復該模式。9個標簽中最左邊的是第一號。例如,模式simaopig被保存在1號寄存器裡,之後用\1來引用它。
x\{m\}或x\{m,\}或x\{m,n\}
字符x的重復出現
‘s\{5\}’,'s\{5,\}’,'s\{5,10\}’
匹配連續出現5個s、至少5個s或5到10個s的行
grep的選項:
觀其語法結構,grep有著很豐富的選項。下面的表格中我會為大家介紹其常用的選項。
選項 |
功能 |
-b
在每一行前面加上其所在的塊號,根據上下文定位磁盤塊時可能會用到
-c
顯示匹配到的行的數目,而不是顯示行的內容
-h
不顯示文件名
-i
比較字符時忽略大小寫的區別
-l(小寫的字母L)
只列出匹配行所在文件的文件名(每個文件名只列一次),文件名之間用換行符分隔
-n
在每一行前面加上它在文件中的相對行號
-s
無聲操作,即只顯示報錯信息,用於檢查退出狀態
-v
反向查找,只顯示不匹配的行
-w
把表達式作為詞來查找,就好像它被\<和\>夾著那樣。只適用於grep(並非所有版本的grep都支持這一功能,譬如,SCO UNIX就不支持)
grep簡單示例:
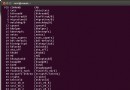
例如第一個表格中,我想查找所有帶有if的行並且顯示行號,如何查找呢?
grep -n if a.html
輸出:
使用過程中,使用最多的參數就是 -v ,但是用著並不爽。
比如說,我想查找一個單詞“UserService”,但是像”*.svn” 這種文件就不用顯示了,我該怎麼做呢?
grep -r "UserService" ./ | grep -v "svn"
但是,如果類似於含有”test、auto_load”之類的文件我也不顯示,怎麼做呢?我之前的做法是:
grep -r "UserService" ./ | grep -v "svn" | grep -v "test" | grep -v "auto_load"
命令很長,而且麻煩,於是就想,grep本身是按照正則表達式來當做選項的,那麼我是不是可以利用到正則表達式的“或|”命令?
grep -r "UserService" ./ | grep -v "svn|test|auto_load"
很顯示,執行結果顯示上面的命令不符合我的需求,於是苦思不得其解。原來,在使用正則表達式選項時,要記得將”|”轉義。最終命令如下:
grep -r "UserService" ./ | grep -v "svn\|prj\|test\|auto_load"
聲明: 本文采用 BY-NC-SA 協議進行授權 | 小小子
轉載轉自《grep 正則表達式及選項》和《grep 正則表達式選項要記得轉義》