AWK Stands for ‘Aho, Weinberger, and Kernighan‘
Awk is a scripting language which is used for processing or analyzing text files. Or we can say that awk is mainly used for grouping of data based on either a column or field , or on a set of columns. Mainly it’s used for reporting data in a usefull manner. It also employs Begin and End Blocks to process the data.
Syntax of awk :
# awk ‘pattern {action}’ input-file > output-file
Lets take a input file with the following data
$ cat awk_file
Name,Marks,Max Marks
Ram,200,1000
Shyam,500,1000
Ghyansham,1000
Abharam,800,1000
Hari,600,1000
Ram,400,1000
Example:1 Print all the lines from a file.
By default, awk prints all lines of a file , so to print every line of above created file use below command :
linuxtechi@mail:~$ awk ‘{print;}’ awk_file
Name,Marks,Max Marks
Ram,200,1000
Shyam,500,1000
Ghyansham,1000
Abharam,800,1000
Hari,600,1000
Ram,400,1000
Example:2 Print only Specific field like 2nd & 3rd.
linuxtechi@mail:~$ awk -F “,” ‘{print $2, $3;}’ awk_file
Marks Max Marks
200 1000
500 1000
1000
800 1000
600 1000
400 1000
In the above command we have used the option -F “,” which specifies that comma (,) is the field separator in the file
Example:3 Print the lines which matches the pattern
I want to print the lines which contains the word “Hari & Ram”
linuxtechi@mail:~$ awk ‘/Hari|Ram/’ awk_file
Ram,200,1000
Hari,600,1000
Ram,400,1000
Example:4 How do we find unique values in the first column of name
linuxtechi@mail:~$ awk -F, ‘{a[$1];}END{for (i in a)print i;}’ awk_file
Abharam
Hari
Name
Ghyansham
Ram
Shyam
Example:5 How to find the sum of data entry in a particular column .
Synatx : awk -F, ‘$1==”Item1″{x+=$2;}END{print x}’ awk_file
linuxtechi@mail:~$ awk -F, ‘$1==”Ram”{x+=$2;}END{print x}’ awk_file
600
Example:6 How to find the total of all numbers in a column.
For eg we take the 2nd and the 3rd column.
linuxtechi@mail:~$ awk -F”,” ‘{x+=$2}END{print x}’ awk_file
3500
linuxtechi@mail:~$ awk -F”,” ‘{x+=$3}END{print x}’ awk_file
5000
Example:7 How to find the sum of individual group records.
Eg if we consider the first column than we can do the summation for the first column based on the items
linuxtechi@mail:~$ awk -F, ‘{a[$1]+=$2;}END{for(i in a)print i”, “a[i];}’ awk_file
Abharam, 800
Hari, 600
Name, 0
Ghyansham, 1000
Ram, 600
Shyam, 500
Example:8 How to find the sum of all entries in second column and append it to the end of the file.
linuxtechi@mail:~$ awk -F”,” ‘{x+=$2;y+=$3;print}END{print “Total,”x,y}’ awk_file
Name,Marks,Max Marks
Ram,200,1000
Shyam,500,1000
Ghyansham,1000
Abharam,800,1000
Hari,600,1000
Ram,400,1000
Total,3500 5000
Example:9 How to find the count of entries against every column based on the first column:
linuxtechi@mail:~$ awk -F, ‘{a[$1]++;}END{for (i in a)print i, a[i];}’ awk_file
Abharam 1
Hari 1
Name 1
Ghyansham 1
Ram 2
Shyam 1
Example:10 How to print only the first record of every group:
linuxtechi@mail:~$ awk -F, ‘!a[$1]++’ awk_file
Name,Marks,Max Marks
Ram,200,1000
Shyam,500,1000
Ghyansham,1000
Abharam,800,1000
Hari,600,1000
AWK Begin Block
Syntax for BEGIN block is
# awk ‘BEGIN{awk initializing code}{actual AWK code}’ filename.txt
Let us create a datafile with below contents
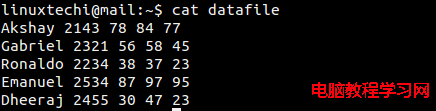
datafile for awk
Example:11 How to populate each column names along with their corresponding data.
linuxtechi@mail:~$ awk ‘BEGIN{print “Names\ttotal\tPPT\tDoc\txls”}{printf “%-s\t%d\t%d\t%d\t%d\n”, $1,$2,$3,$4,$5}’ datafile

Example:12 How to change the Field Separator
As we can see space is the field separator in the datafile , in the below example we will change field separator from space to “|”
linuxtechi@mail:~$ awk ‘BEGIN{OFS=”|”}{print $1,$2,$3,$4,$5}’ datafile