Linux的內核十分穩定,但仍不可避免會遇到崩潰的情況,獲取內核崩潰時的內存鏡像,有助於分析系統在崩潰前發生了什麼,分析原因並修復錯誤,進而進一步提升系統的穩定性。
【正文】
一 kdump簡介
kdump 是目前最有效的linux內存鏡像收集機制,廣泛應用於各大linux廠商的各種產品中,在 debug 內核方面起著不可替換的重要作用。
Kdump 是一種基於 kexec 的 Linux 內核崩潰捕獲機制,將 kernel 崩潰前的內存鏡像保存,程序員通過分析該文件找出 kernel 崩潰的原因,從而進行系統改進。
Kdump用於對內存鏡像的轉儲,它不但可以轉儲內存鏡像到本地硬盤,還可以將內存鏡像通過NFS,SSH等協議轉儲到不同機器的設備上。
Kdump分為兩個組件:Kexec和Kdump。
Kexec是一種內核的快速啟動工具,可以使新的內核在正在運行的內核(生產內核)的上下文中啟動,而不需要通過耗時的BIOS檢測,方便內核開發人員對內核進行調試。Kdump是一種有效的內存轉儲工具,啟用Kdump後,生產內核將會保留一部分內存空間,用於在內核崩潰時通過Kexec快速啟動到新的內核,這個過程不需要重啟系統,因此可以轉儲崩潰的生產內核的內存鏡像。;
二 kdump的安裝配置
2.1 安裝包
Kdump 用到的各種工具都在 kexec-tools 中。kernel-debuginfo 則是用來分析 vmcore 文件。從 rhel5 開始,kexec-tools 已被默認安裝在發行版。而如果需要調試 kdump 生成的 vmcore 文件,則需要手動安裝 kernel-debuginfo 包。檢查安裝包操作,注意kernel-debuginfo和kernel-debuginfo的版本要和內核版本一致:

2.2 配置kdump配置文件
在/boot/grub/grub.conf文件中添加內核參數"crashkernel=Y@X",這裡,Y 是為 kdump 捕捉內核保留的內存,X 是保留部分內存的開始位置。對於 i386 和 x86_64, 編輯 /etc/grub.conf, 在內核行的最後添加"crashkernel=128M" 。另外建議不要設置為crashkernel=auto,因為rhel6引入的”auto”已經要被拋棄了。
2.3 配置kdump的一些參數。
kdump默認將文件存放在本地硬盤的/var/crash/目錄下,該位置可以是本地文件系統的某個目錄,或者某個塊設備,或者通過網絡存儲在其他機器上,可以修改文件:
cat /etc/kdump.conf
…
#raw /dev/sda5 (如果寫入到裸設備上,需要取消該行的注釋)
#ext4 /dev/sda3 (指定寫入設備的文件系統類型和分區)
#ext4 LABEL=/boot (支持LABEL以及UUID來標識設備)
#ext4 UUID=03138356-5e61-4ab3-b58e-27507ac41937
#net my.server.com:/export/tmp (NFS方式寫入)
#net
[email protected] (SSH方式寫入)
path /var/crash (內存鏡像文件的保存路徑)
core_collector makedumpfile -c --message-level 1 -d 31
(設置保存內存鏡像內容的級別,-c表示使用makedumpfile壓縮數據,--message-devel 1表示提示信息的級別,1表示只顯示進度信息。-d 31表示不復制所有可以去掉的內存頁,包括zero page, cache page, cache private, user data, free page等)
#default shell
(表示如果kdump轉儲內存鏡像失敗後的執行的動作,默認為掛載根文件系統並執行/sbin/init進程,可更改為reboot, halt, poweroff, shell等)
2.4 將kdump服務設置為開機自啟動。

2.5 驗證配置是否成功。
使用命令出發內核的崩潰,如在指定目錄下生成內核鏡像文件則表示配置成功。


三 crash簡介
crash是目前廣泛使用的 linux 內核崩潰轉儲文件的分析工具,掌握crash的使用技巧,對於分析定位內核崩潰的問題,有著非常重要的作用。
對於內核開發人員,crash 已經成了必不可少的一個工具。
四 crash配置以及初步使用
4.1 檢查安裝包
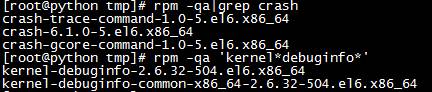
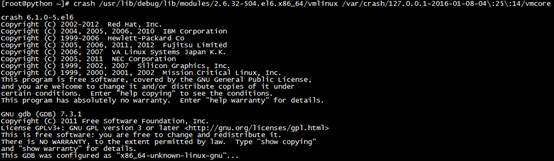
4.2 使用crash分析內存轉儲文件。
兩個參數分別是debug kernel 和 dump file,即帶有調試信息的內核以及崩潰產生的內核轉儲文件:
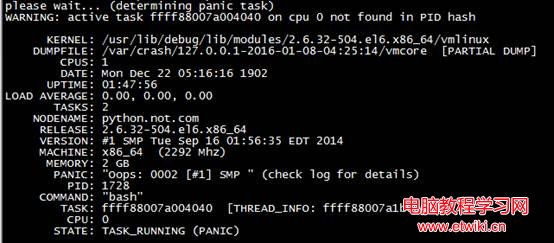
各項參數的意義為:
Kernel——表示調試內核的位置和版本信息
DUMPFILE——表示所分析的內存轉儲鏡像
CPUS——表示本機的CPU數目
DATE——表示內核崩潰發生的時間
UPTIME——表示內核已正常運行的時間
LOAD AVERAGE——表示內核崩潰時系統的負載
TASKS——表示內核崩潰時系統運行的任務數
NODENAME——表似乎內核崩潰的機器的主機名
RELEASE——表示內核的發布版本
VERSION——表示內核的其他版本信息
MACHINE——表示CPU架構和主頻信息
MEMORY——表示發生內核崩潰的系統的內存大小
PANIC——表示崩潰的類型。可能有SysRq,即通過系統請求造成的內核崩潰;Oops,表示內核發生了不可預測或不正確的行為,這時會殺死相應的進程,內核可能恢復正常,也可能處於一種不確定的狀態,進而導致內核的Panic;Pannic,內核崩潰,即發生了嚴重且不可修復的錯誤,如發生了非法的地址訪問,強制加載或卸載內核模塊,以及硬件錯誤等等
PID——表示導致內核崩潰的的進程號
COMMAND——表示導致內核崩潰的進程名稱
TASK——表示導致內核崩潰的進程訪問的內存地址
CPU——表示導致內核崩潰的進程占用的CPU數目
STATE——表示導致內核崩潰的進程的運行狀態
以上信息可用於初步分析內核崩潰的原因,內核態有三種出錯情況,分別是bug, oops和panic。bug屬於輕微錯誤,oops代表某一用戶進程出現錯誤,需要殺死用戶進程,這時如果用戶進程占用了某些信號鎖,這些信號鎖將永遠不會得到釋放,這會導致系統潛在的不穩定性。Panic是嚴重錯誤,代表整個系統崩潰。深入的分析需要使用更多的命令進行追蹤和查找,並需要對內核的運行機制和內核開發編程有一定的了解。
4.3 crash常用命令
help #查看命令的幫助信息,也可用man命令
h #查看歷史命令,相當於shell下的history
log #該命令用於打印出內存的日志信息
bt #該命令用於獲取當前線程的調用堆棧
foreach bt #該命令用於獲取所有線程的調用堆棧
ps #該命令用於查看內核崩潰時的進程信息
vm #該命令用於查看當前的內核上下文的虛擬內存信息
files #該命令用於查看當前的內核上下文中打開的文件
exit or q #退出Crash
4.4 使用 bt 命令查看堆棧
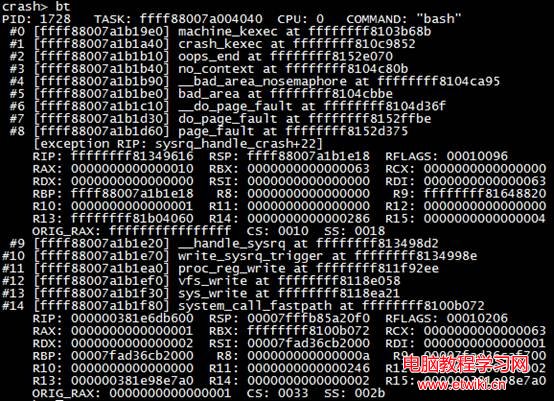
[exception RIP: sysrq_handle_crash+22]字段顯示,指令指針發生異常,原因為內核函數sysrq_handle_crash發生錯誤,偏移量為22,可以看出,這也和文件系統相關。
CS: 0010字段表示代碼段寄存器的信息,其最低位為0,表示當前進程的特權等級(CPL)為0,表示錯誤發生在內核空間。
4.5 log 命令可以打印系統消息緩沖區,從而可能找到系統崩潰的線索(截圖已省略部分行,只顯示末尾)
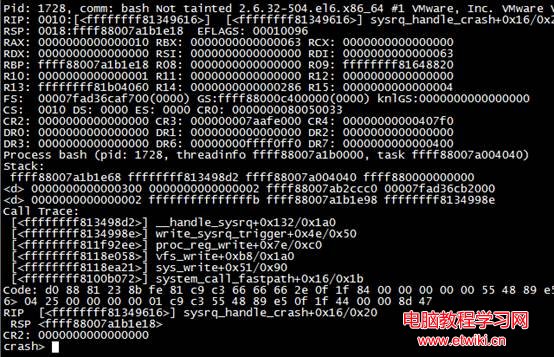
與bt結果類似,內核通過Call Trace打印出來系統調用的堆棧信息,以供分析。
4.6 ps 命令用於顯示進程的狀態,(如圖)帶 > 標識代表是活躍的進程。

其中swapper表示系統的交換進程,是內核的一部分,負責內核任務的調度,其pid為0,每個CPU都會有一個swapper進程。這裡可以看到導致內核崩潰的進程bash的狀態,進程號為1728。
4.7 files命令可以查看當前的內核上下文中打開的文件

可以看到有相關的文件操作/proc/sysrq-trigger
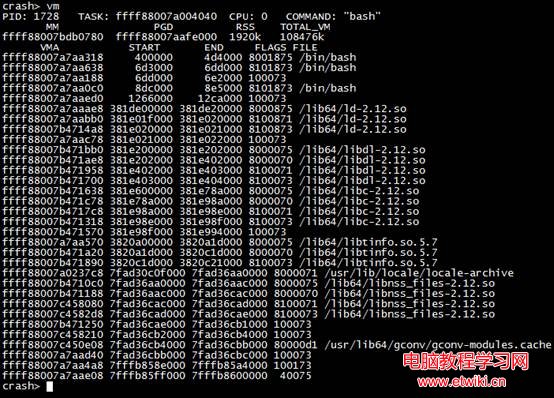
4.8 vm命令查看虛擬內存信息
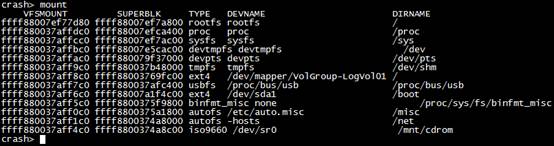
4.9 mount命令查看掛載狀態
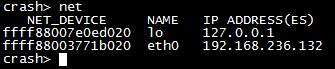
4.10 net命令查看簡單的網絡信息
五 結論
當 linux 系統內核發生崩潰的時候,可以通過 kdump 等方式收集內核崩潰之前的內存,生成一個轉儲文件 vmcore。內核開發者通過分析該 vmcore 文件就可以診斷出內核崩潰的原因,從而進行
操作系統的代碼改進。crash就是一個被廣泛使用的內核崩潰轉儲文件分析工具。通過kdump和crash的親密配合,可以排除不少問題。