與windows系統一樣,linux操作系統也會存在很多問題和故障,很多linux新手都害怕故障,面對出現的問題顯得無可奈何,更有甚者,由此放棄了linux,其實,我們不應該懼怕問題,學習就是一個發現問題與解決問題的過程,只要掌握了解決問題的基本思路,一切故障都會迎刃而解,當然前提是我們已經具備了解決問題的思路和扎實的知識功底。
一、處理linux系統故障的思路
作為一名合格的linux系統管理員,一定要有一套清晰、明確的解決故障思路,當問題出現時,才能迅速定位、解決問題,這裡給出一個處理問題的一般思路:
重視報錯提示信息:每個錯誤的出現,都是給出錯誤提示信息,一般情況下這個提示基本定位了問題的所在,因此一定要重視這個報錯信息,如果對這些錯誤信息視而不見,問題永遠得不到解決。
查閱日志文件:有時候報錯信息只是給出了問題的表面現象,要想更深入的了解問題,必須查看相應的日志文件,而日志文件又分為系統日志文件(/var/log)和應用的日志文件,結合這兩個日志文件,一般就能定位問題所在。
分析、定位問題:這個過程是比較復雜的,根據報錯信息,結合日志文件,同時還要考慮其它相關情況,最終找到引起問題的原因。
解決問題:找到了問題出現的原因,解決問題就是很簡單的事情了。
從這個流程可以看出,解決問題的過程就是分析、查找問題的過程,一旦確定問題產生的原因,故障也就隨之解決了。
二、 忘記linux root密碼
這個問題出現的幾率是很高的,不過,在linux下解決這個問題也很簡單,只需重啟linux系統,然後引導進入linux的單用戶模式(init 1),由於單用戶模式是不需要輸入登錄密碼的,因此,可以直接登錄系統,修改root密碼即可解決問題。
下面是詳細的處理方法,這裡我們以Redhat linux為基准,操作步驟如下:
(1) 重啟系統,待linux系統啟動到grub引導菜單時,找到當前系統引導選項(可以按方向鍵展開隱藏的菜單,單處理器只有一個引導項,多處理器有3個或3個以上引導項,一般默認選項就是系統當前引導選項)。
(2) 通過方向鍵將光標放到當前系統引導項上,然後按鍵盤字母“e”,進入編輯狀態。
(3) 然後通過上下鍵,選中帶有kernel指令的一行,繼續按鍵盤字母“e”,編輯該行,在行末尾加個空格,然後添加single,類似與這樣:
kernel /vmlinuz-2.6.18-8.el5 ro root=LABEL=/ rhgb quiet single
(4) 修改完成,按回車鍵,返回到剛才的界面。
(5) 最後按鍵盤“b”,系統開始引導。
這樣系統就啟動到了單用戶模式下,這裡的單用戶根windows下的安全模式類似,在單用戶模式下,只是啟動最基本的系統,網絡以及應用服務均不啟動。單用戶模式啟動完畢,系統會自動進入到命令行狀態下,類似與“sh-3.1#”,然後直接執行passwd,回車,系統會提示輸入新的root密碼兩次,最後會看到修改密碼成功的提示,這樣就完成了root密碼的修改。如果需要正常啟動系統,現在只需輸入“init 3”,就進入了多用戶模式。用root用戶重新登錄系統,看看設置的新密碼是否生效。
三 linux系統無法啟動的解決辦法
導致linux無法啟動的原因有很多,常見的原因有如下幾種:
文件系統配置不當,比如/etc/inittab文件、/etc/fstab文件等配置錯誤或丟失,導致系統錯誤,無法啟動。
非法關機,導致root文件系統破壞,也就是linux根分區破壞,系統無法正常啟動
Linux內核崩潰,從而無法啟動
系統引導程序出現問題,比如grub丟失或者損壞,導致系統無法引導啟動。
硬件故障,比如主板、電源、硬盤等出現問題,導致linux無法啟動。
從這些常見的故障可知,導致系統無法啟動的主要有兩個問題,硬件原因和操作系統原因,對於硬件出現的問題,只需通過更換硬件設備,即可解決,而對於操作系統出現的問題,雖然出現的問題可能千差萬別,不過在多數情況下都可以用相對簡單統一的一些方法來恢復系統,下面我們就針對上面提出的幾個問題,結合Redhat Linux系統環境,給出一些常用的、普遍的解決問題的方法。
1./etc/fstab文件丟失,導致系統無法啟動
/etc/fstab文件存放了系統中文件系統的相關信息,如果正確的配置了該文件,那麼在linux啟動時,系統會讀取此文件,自動掛載linux的各個分區,如果此文件配置錯誤,或者丟失,就會導致系統無法啟動,具體的故障現象是在檢測mount partition時出現:
starting system logger
此後系統啟動就停止了。
針對這個問題,我們的第一思路就是想辦法恢復/etc/fstab這個文件的信息,只要恢復了此文件,系統就能自動掛載每個分區,正常啟動。可能很多讀者首先想到的是將系統切換到單用戶模式下,然後手動掛載分區,最後結合系統信息,重建/etc/fstab文件。
但是這種方法是行不通的,因為fatab文件丟失導致linux無法掛載任何一個分區,即使linux還能切換到單用戶下,那麼此時的系統也只是一個read-only的文件系統,無法向磁盤寫入任何信息。
我們介紹另外一個方法,就是利用linux rescue修復模式登錄系統,進而獲取分區和掛載點信息,重構/etc/fstab文件。
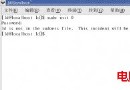
這裡以rhel5為例,首先將系統第一章光盤放入光驅,設置BOIS從光驅啟動,這樣系統就從光驅引導,然後在boot後輸入:linux rescue,如圖1所示:

圖1設置linux進入修復模式
接著系統自動開始引導,進入圖2所示畫面:
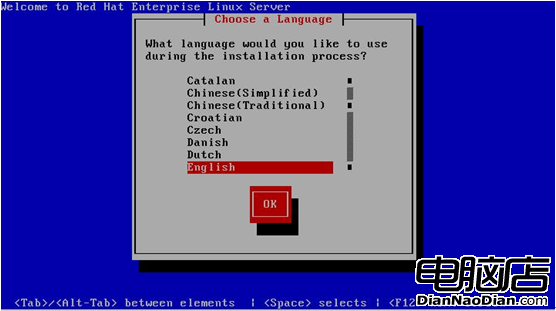
圖2 選擇語言
這裡是選擇模式使用的語言,可以按照自己需要設定,我們這裡選擇“English“,然後按tab鍵,選中“ok”,回車進入下一步。
下面進入的是鍵盤選擇界面,如圖3所示,這裡選擇默認的“us”即可。
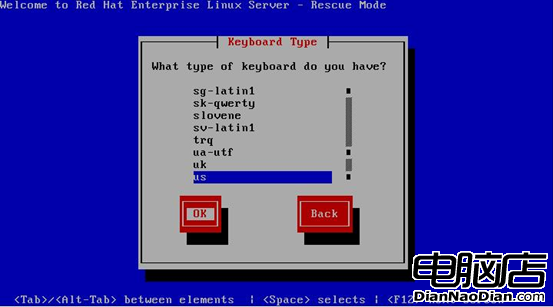
圖3 選擇鍵盤類型
下面進入網絡配置界面,如圖4所示:
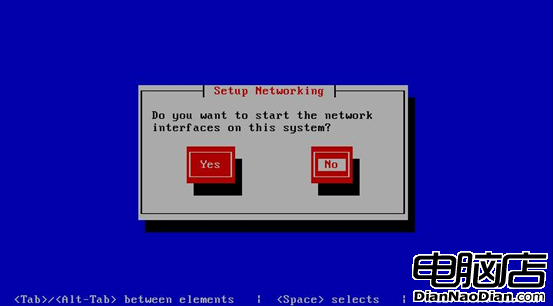
圖4 是否啟用網絡
這裡是選擇是否啟用網絡,由於系統已經無法啟動,我們已經在linux系統上進行操作了,啟用網絡與否都無所謂。這裡選擇不啟用。
下面到了最關鍵的步驟了,如圖5所示,修復模式會自動將系統的所有分區掛載到/mnt/sysimage目錄下,選擇“Continue”,則修復環境進入到read-write狀態下,可以對分區進行讀寫操作,選擇“Read-Only”,修復環境進入到只讀模式,由於我們要重建fstab文件到/etc目錄下,因此選擇“Continue”進入可讀寫模式下。
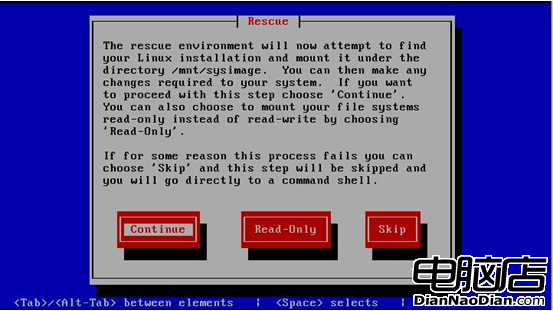
圖5 選擇修復模式的啟動方式
下面是一個友情提示界面,如圖6所示,由於fstab文件丟失,修復模式找不到任何可掛載的分區,從這裡可知,修復模式在這裡也讀取/etc/fstab文件,回車,進入下一步。
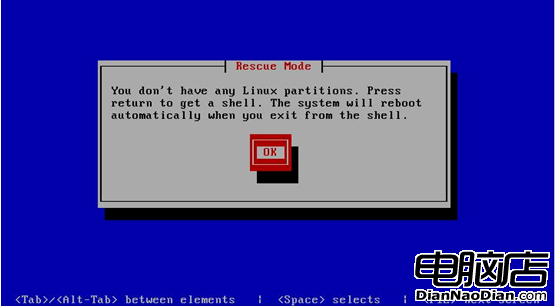
圖6 無法掛載系統任何分區
下面就進入了修復環境下,可以進行操作了。如圖7所示

圖7 修復模式命令行
上面詳細演示了如何進入linux的修復模式,其實很多情況下,linux無法啟動時,都可以通過這個方式登錄系統進行修復和更改操作。
下面是恢復/etc/fstab文件的詳細過程:
首先查看一下系統分區情況,如下所示:
sh-3.1# fdisk -l
Disk /dev/sda: 42.9 GB, 42949672960 bytes
255 heads, 63 sectors/track, 5221 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Device Boot Start End Blocks Id System
/dev/sda1 * 1 25 200781 83 Linux
/dev/sda2 26 1300 10241437+ 83 Linux
/dev/sda3 1301 1682 3068415 83 Linux
/dev/sda4 1683 5221 28427017+ 5 Extended
/dev/sda5 1683 1873 1534176 83 Linux
/dev/sda6 1874 2064 1534176 83 Linux
/dev/sda7 2065 2255 1534176 83 Linux
/dev/sda8 2256 2382 1020096 83 Linux
/dev/sda9 2383 2484 819283+ 82 Linux swap / Solaris
/dev/sda10 2485 5221 21984921 83 Linux
因為分區並沒有損壞,通過fdisk命令可以查看到系統分區的完整信息,但是每個分區對應的label name信息我們還不知道,下面通過e2label命令查看每個分區對應的label name:
sh-3.1# e2label /dev/sda1
/boot
sh-3.1# e2label /dev/sda2
/usr
sh-3.1# e2label /dev/sda3
/
sh-3.1# e2label /dev/sda5
/var
sh-3.1# e2label /dev/sda6
/tmp
sh-3.1# e2label /dev/sda7
/home
sh-3.1# e2label /dev/sda8
/opt
sh-3.1# e2label /dev/sda10
/webdata
這樣,就得到了所有分區的掛載點信息,接下來就可以構造一個fstab文件了。
小技巧:可以參考其它系統中fstab文件的格式,結合本系統的分區和掛載點信息,構造出自己的fstab文件來。
由於fstab文件是存放在系統根目錄下的,因此需要掛載原來系統的根分區,從上面可知根分區對應的設備名為/dev/sda3,接著在修復模式創建的臨時根分區下創建一個掛載點,然後掛載原來系統的根分區。操作過程如下所示:
sh-3.1# pwd
/
sh-3.1# mkdir temp
sh-3.1# mount /dev/sda3 /temp
sh-3.1# df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev 515644 0 515644 0% /dev
/tmp/loop0 79872 79872 0 100% /mnt/runtime
/dev/sda3 2972268 259916 2558932 10% /temp
這樣以來,原有根分區的文件全部掛載到了/temp目錄下,接著就可以創建我們需要的fatab文件了。
sh-3.1# vi /temp/etc/fstab
LABEL=/ / ext3 defaults 1 1
LABEL=/boot /boot ext3 defaults 1 2
LABEL=/cicro /cicro ext3 defaults 1 2
devpts /dev/pts devpts gid=5,mode=620 0 0
tmpfs /dev/shm tmpfs defaults 0 0
LABEL=/home /home ext3 defaults 1 2
LABEL=/opt /opt ext3 defaults 1 2
proc /proc proc defaults 0 0
sysfs /sys sysfs defaults 0 0
LABEL=/tmp /tmp ext3 defaults 1 2
LABEL=/usr /usr ext3 defaults 1 2
LABEL=/var /var ext3 defaults 1 2
LABEL=SWAP-sda9 swap swap defaults 0 0
配置完畢,保存退出,然後重啟系統。
sh-3.1#reboot
2、root文件系統破壞,導致系統無法啟動
Linux下普遍采用的是ext3文件系統,ext3是一個具有日志記錄功能的日志文件系統,可以進行簡單的容錯和恢復,但是在一個高負荷讀寫的ext3文件系統下,如果突然發生掉電,就很有可能發生文件系統內部結構不一致,導致文件系統破壞。
Linux在啟動時,會自動去分析和檢查系統分區,如果發現文件系統有簡單的錯誤,會自動修復,如果文件系統破壞比較嚴重,系統無法完成修復時,系統就會自動進入單用戶模式下或者出現一個交互界面,提示用戶介入手動修復,現象類似下面所示:
checking root filesystem
/dev/sdb5 contains a file system with errors, check forced
/dev/sdb5:
Unattached inode 68338812
/dev/sdb5: UNEXPECTED INCONSISTENCY; RUN fsck MANUALLY
(i.e., without -a or -p options)
FAILED
/contains a file system with errors check forced
an eror occurred during the file system check
****dropping you to a shell;the system will reboot
****when you leave the shell
Press enter for maintenance
(or type Control-D to continue):
give root password for maintenance
從這個錯誤可以看出,系統根分區文件系統出現了問題,系統在啟動時無法自動修復,然後進入到了一個交互界面,提示用戶進行系統修復。
這個問題發生的機率很高,引起這個問題的主要原因就是系統突然掉電,引起文件系統結構不一致。一般情況下解決此問題的辦法是采用fsck命令,進行強制修復。
根據上面的錯誤提示,當按下“Control-D”組合鍵後系統自動重啟,當輸入root密碼後進入系統修復模式,在修復模式下,可以執行fsck命令,具體操作過程如下:
[root@localhost /]#umount /dev/sdb5
[root@localhost /]#fsck .ext3 -y /dev/sdb5
e2fsck 1.39 (29-May-2006)
/ contains a file system with errors, check forced.
Pass 1: Checking inodes, blocks, and sizes
Pass 2: Checking directory structure
Pass 3: Checking directory connectivity
Pass 4: Checking reference counts
Inode 6833812 ref count is 2, should be 1. Fix<y>? yes
Unattached inode 6833812
Connect to /lost+found<y>? yes
Inode 6833812 ref count is 2, should be 1. Fix<y>? yes
Pass 5: Checking group summary information
Block bitmap differences: -(519--529) -9273
Fix<y>? yes
…… ……
/: ***** FILE SYSTEM WAS MODIFIED *****
/: 19/128520 files (15.8% non-contiguous), 46034/514048 blocks
上面就是fsck修復受損文件系統的過程,fsck詳細用法在本書第四章有詳細的講述,這裡不在多講。需要注意的是,在執行fsck的時候,一定要先卸載要修復的分區,然後再執行修復操作,切記!
三、其它故障的一般解決方案
如果是linux的引導程序出現問題,那麼也可以通過光盤引導的方式進入linux修復模式,然後修改對應的引導程序或者重新安裝引導程序。
如果linux內核崩潰或者丟失,同樣可以先進入linux rescue下,然後加載root分區,最後重新編譯內核。
如果出現了最壞的情況,文件系統破壞嚴重,同時內核也崩潰,那麼此時重新安裝系統反而比較容易,在這種情況下可以先將linux上有用的數據和文件備份轉移到其它設備,然後對整個文件系統進行全新安裝。
在這裡我們不可能對每個出現的問題,都給出詳細的解決方案,問題都是千差萬別的,每個問題的處理都不盡相同,本書要傳授給大家的是當linux系統出現問題後,解決問題的一般思路和通用策略,熟練掌握了這些技巧,處理任何linux問題都能游刃有余。
四、 linux下常見網絡故障處理
linux網絡服務功能非常強大,在linux上可以部署Web Server、DNS Server、Mail Server、Db server、Ftp server等等,但是也由此產生了很多網絡問題,據統計,在linux系統下產生的故障,有60%來自網絡方面,40%來自系統本身,可見熟練解決linux下故障,對於熟練掌握linux有著巨大的幫助。
解決linux網絡問題的順序應該是首先從Linux操作系統自身的底層網絡開始,然後逐步有點及面的向外擴展,網絡問題的一般解決流程為:
網絡硬件傳輸問題,可以通過檢查網線是否正常,網卡、集線器、路由器、交換機等是否正常來確認是否由硬件問題造成網絡故障。
檢查網卡是否能正常工作,可以從網卡是否正常加載、網卡IP設置是否正確、系統路由是否設置正確3個方面進行檢查確認。
檢查DNS是否設定正確,可以從linux的DNS客戶端配置文件/etc/resolv.conf,本地主機文件/etc/hosts進行檢查確認。
服務是否正常打開,可以通過telnet或者netstat命令的方式檢測服務是否開啟。
訪問權限是否打開,可以從本機iptables防火牆、linux內核強制訪問控制策略selinux兩方面入手,進行檢查確認。
局域網主機之間聯機是否正常; 可以通過ping自身IP,ping局域網其它主機IP,ping網關地址來確認局域網是否連接正常。
接下來,我們就針對上面給出的解決網絡問題的一般思路,詳細展開講述。
1. 檢查網絡硬件傳輸問題
檢查網絡故障,首先要排除的是網絡硬件設備是否存在問題,比如網線是否正常,網卡、集線器、路由器、交換機等是否正常,這些是網絡正常運行的基本條件,如果發現某些設備出現故障,只需更換硬件即可解決問題。
2.檢查網卡是否能正常工作
(1)檢查網卡是否正常加載
通過lsmod、ifconfig命令可以判斷網卡是否正常加載,如果通過ifconfig可以顯示網絡接口(eth0、eth1等等)的配置信息,表示系統已經認到了網卡驅動程序,檢測到了網絡設備,網卡加載正常。
(2)檢查網卡IP設置是否正確
接下來就要檢查網卡的軟件設定,比如IP是否配置,配置是否正確,確保IP的配置和局域網其它計算機配置沒有沖突。
(3)檢查系統路由表信息是否正確
最後就是要檢查系統的路由表設置是否正確,如果一個linux系統有兩塊網卡,同時兩塊網卡設置的IP不在一個網段,要特別注意系統路由表的設置。
例如下面這個系統的網絡接口信息:
[root@webserver ~]# ifconfig
eth0 Link encap:Ethernet HWaddr 00:12:3F:FF:65:24
inet addr:10.10.1.239 Bcast:10.10.1.255 Mask:255.255.255.0
inet6 addr: fe80::212:3fff:feff:6524/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:20632289 errors:0 dropped:0 overruns:0 frame:0
TX packets:20223702 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:793608426 (756.8 MiB) TX bytes:2567481473 (2.3 GiB)
Interrupt:201
eth1 Link encap:Ethernet HWaddr 00:12:3F:FF:65:25
inet addr:192.168.200.30 Bcast:192.168.200.255 Mask:255.255.255.0
inet6 addr: fe80::212:3fff:feff:6525/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:15496910 errors:0 dropped:0 overruns:0 frame:0
TX packets:8028739 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:1048038084 (999.4 MiB) TX bytes:3195989266 (2.9 GiB)
Interrupt:209
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:508961 errors:0 dropped:0 overruns:0 frame:0
TX packets:508961 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:574086961 (547.4 MiB) TX bytes:574086961 (547.4 MiB)
從上面輸出可知,本系統有兩塊網卡,分別配置不同網段的IP地址,假定eth0通過映射的方式對外提供ssh連接服務,而eth1僅供局域網主機之間共享數據使用。
現在的問題是,外界無法ssh遠程登錄到此系統,而網卡加載沒有問題,網卡IP設置也沒問題,接下來看看此系統的路由設置:
[root@webserver ~]# route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
10.10.1.0 * 255.255.255.0 U 0 0 0 eth0
192.168.200.0 * 255.255.255.0 U 0 0 0 eth1
default 192.168.200.1 0.0.0.0 UG 0 0 0 eth1
到這裡,問題已經基本排查出來了:從route的輸出可知,linux的缺省路由是192.168.200.1,而192.168.200段的IP僅僅供局域網主機之間共享數據使用,沒有連接出去的訪問權限,因而,外界無法連接到linux系統,也是理所當然的事情了。
定位了問題,解決方法很簡單,刪除192段的缺省路由,然後增加10段的缺省路由即可:
[root@webserver ~]# route delete default
[root@webserver ~]#route add default gw 10.10.1.254
此時外界就可以通過ssh服務遠程連接到linux系統了。
3.檢查DNS解析文件是否設置正確
在Linux系統中,有兩個文件用來指定系統到哪裡尋找相關域名解析的庫。分別是文件/etc/host.conf和/etc/nsswitch.conf。
/etc/host.conf文件指定系統如何解析主機名,Linux通過域名解析庫來獲得主機名對應的IP地址。下面是RedHat Linux安裝後缺省的/etc/host.conf內容:
order hosts,bind
其中,order指定主機名查詢順序,這裡表示首先查找/etc/hosts文件對應的解析,如果沒有找到對應的解析,接著就根據/etc/resolve.conf指定的域名服務器進行解析。
/etc/nsswitch.conf文件是由SUN公司開發的,用於管理系統中多個配置文件查詢的順序,由於nsswich.conf提供了更多的資源控制方式,nsswich.conf文件現在已經基本取代了hosts.conf,雖然LINUX系統中默認這兩個文檔都存在,但實際上起作用的是nsswitch.conf文件。
nsswitch.conf文件每行的配置都以一個關鍵字開頭,後跟冒號,緊接著是空白,然後是一系列方法的列表。
例如這段信息:
hosts: files dns
表示系統首先查詢主機庫文件,如果沒有找到對應的解析,接著會去DNS配置文件指定的DNS服務器進行解析。
清楚了linux下域名解析的原理和過程,我們就可以根據這兩個文件的設定,確定解析的順序,從而判斷出域名解析可能出現的問題。
4.檢查服務是否正常打開
在一個應用出現故障時,必須要檢查的就是服務本身,比如服務是否開啟,配置是否正確等等,檢查服務是否正確打開,分為兩步,第一步是查看服務的端口是否打開:
例如,我們不能用root用戶ssh登錄到192.168.60.133這台linux服務器,首先檢查sshd服務的22端口是否打開:
[root@localhost init.d]# telnet 192.168.60.133 22
SSH-2.0-OpenSSH_4.3
這個輸出表示192.168.60.133的22端口對外開放,或者可以說sshd服務是處於打開狀態。如果沒有任何輸出,可能是服務沒有啟動,或者服務端口被屏蔽。
也可以在服務器上通過netstat命令檢查22端口是否打開:
[root@localhost xinetd.d]# netstat -ntl
tcp 0 0 0.0.0.0:3306 0.0.0.0:* LISTEN
tcp 0 0 :::80 :::* LISTEN
tcp 0 0 :::22 :::* LISTEN
可以看到,22端口在服務器上是打開的,同時,服務器上打開的還有3306、80端口。
接著進行第二步的檢查,既然服務已經打開,可能是sshd服務配置的問題,檢查sshd服務端配置文件/etc/ssh/sshd_config,發現有下面一行信息:
PermitRootLogin no
由此可知是ssh服務端配置文件限制了root用戶不能登錄系統,如果需要root登錄系統,只需更改為如下即可:
PermitRootLogin yes
到這裡為止,我們通過對端口和服務配置文件的層層檢查,最終找到了問題的根源。需要說明的是,這裡的重點不是講述如何讓root登錄linux系統,而是要通過這個例子讓讀者學會處理類似問題的思路和方法。
5.檢查訪問權限是否打開
(1)檢查系統防火牆iptables的狀態
當某些服務不能訪問時,一定要檢查是否被linux本機防火牆iptables屏蔽了,可以通過iptables -L指令查看iptables的配置策略,例如我們不能訪問某台linux服務器提供的www服務,通過檢查,系統網絡、域名解析都正常,並且服務也正常啟動,然後檢查了服務器的iptables策略配置,信息如下:
[root@localhost ~]# iptables -L -n
Chain INPUT (policy DROP)
target prot opt source destination
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy DROP)
target prot opt source destination
從上面的輸出可知,這個linux服務器僅僅設置了預設策略,而致命的是將INPUT鏈和OUTPUT鏈都設置為DROP,也就是所有外部數據不能進入服務器,服務器數據也不能出去,這樣的設置相當於沒有網絡。
為了能訪問這台服務器提供的www服務,增加兩條策略即可:
[root@localhost ~]#iptables -A INPUT -i eth0 -p tcp --dport 80 -j ACCEPT
[root@localhost ~]#iptables -A OUTPUT -p tcp --sport 80 -m state --state ESTABLISHED -j ACCEPT
這樣以來,internet上的其他人就能訪問我們的www服務了。
(2)檢查selinux是否打開
在前面的章節,我們已經講述過selinux的含義和功能,它可以最大限度地保證Linux系統的安全,但是selinux有時也會給linux下軟件的運行帶來一些問題,這些問題大部分是對selinux不了解造成的,為了迅速定位問題,最簡單的方法是先關閉selinux,然後測試軟件運行是否正常,這不是個好方法,但是對於判斷問題往往是很有用的,selinux是個很好的安全訪問控制軟件,可是如果你還不能熟練運用selinux訪問控制策略的話,還是建議將它暫時關閉,等到對linux有了更深入的認識後,再開啟selinux不失為一個明智的策略。
6.檢查局域網主機之間聯機是否正常
通過上面5步的檢查,linux系統自身的問題已經基本排除,接下來需要擴展到linux主機之外的網絡環境,檢查網絡之間的連通是否存在故障,可以先通過ping命令測試局域網主機之間的連通性,然後ping網關,檢測主機到網關的通信是否正常。
任何網絡故障的出現,都是有原因的,只要我們根據上面給出的解決問題流程,逐一排查,99%的問題都能得到很好的解決。