電腦店訊
1 概述
1977年,DEC公司推出了以VAX為結點機的松散耦合的集群系統,並成功地將VMS操作系統移植到該系統上。20世紀90年代以來,隨著RISC技術的發展和高性能網絡產品的出現,集群系統在性能價格比(Performance/Cost)、可擴展性(Scalability)、可用性(Availability)等方面都顯示出了很強的競爭力,尤其是它在對現有單機上的軟硬件產品的繼承和對商用軟硬件最新研究成果的快速運用方面表現出了傳統大規模並行處理機(Massively Parallel Processor,MPP)無法比擬的優勢。
目前,集群系統已在許多領域獲得應用。可以預見,隨著對稱多處理機(Symmetric Multiprocessor,SMP)產品的大量使用和高性能網絡產品的完善,以及各種軟硬件支持的增多和系統軟件、應用軟件的豐富,新一代高性能集群系統必將成為未來高性能計算領域的主流平台之一。具有代表性的集群系統有IBM的SP2、SGI 的POWER CHALLENGEarray、Microsoft的Wolfpack、DEC的TruClusters、SUN的SPARC cluster 1000/2000PDB以及Berkeley NOW等。我國國家智能計算機研究開發中心的曙光-1000A、曙光-2000I和曙光-2000II也都屬於集群系統的並行計算機。簡單地說,並行計算機就是用若干(幾到幾千)處理器並行執行一個作業,以提高計算效率。並行計算機的結構、規模、性能可以有很大的差異,其價格也就可以從人民幣數萬元到數億元。以較低的投資,用若干台性能較高的PC機組裝成集群並行計算機,采用Linux操作系統以及目前在各類並行機上通用的信息傳遞接口MPI並行環境,以此為起步發展並行計算和研究,是一個合適的選擇。計算機科學技術的發展在高性能計算領域為其他科學技術的發展提供了越來越寬廣的平台。另一方面,科學技術的發展對高性能計算環境(硬、軟件)不斷提出更高的要求。以磁約束聚變研究為例,磁約束受控核聚變研究是以探求未來能源為目標的。托卡馬克(TOKAMAK)是磁約束受控核聚變研究中進展最快、參數最高的研究途徑。20世紀90年代在歐美的托卡馬克上成功進行的氘-氚聚變反應實驗,使得磁約束受控核聚變的科學可行性得到了初步證實。目前人們正從作為聚變能源的要求來開展托卡馬克研究。托卡馬克的研究對象是高溫等離子體,是一個具有巨大數目(例如1020個)自由度的極為復雜的非線性系統。數值模擬是主要的研究手段之一。在我國,隨著核聚變等離子體物理研究(托卡馬克實驗、理論和數值模擬)不斷取得新的進展,特別是國家大科學工程HT-7U超導托卡馬克計劃的實施,對高性能計算提出了更高的要求。針對特定的研究領域,在一定的財力資源下,集群並行計算機可以為數值模擬的發展提供串行計算機系統所無法比擬的高效平台。
2 Beowulf集群系統簡介
Linux環境下的集群系統中比較有影響的是Beowulf集群。Beowulf集群的研究是由美國國家航空航天局(NASA)於1994年啟動的。1994年,Thomas Sterling和Don Becker等人構建了一台由以太網連接的擁有16個DX4處理器的集群。他們把這個集群計算機叫作Beowulf,主要用來進行地球、空間科學的研究。Beowulf的主要目的是使用普通的、相對廉價的計算機構建能夠處理繁重計算的集群。此後,Beowulf的思想迅速被世界上許多研究機構認同和接受。在Beowulf集群上運行的軟件是Linux操作系統、並行虛處理機(Parallel Virtual Machine,PVM)和消息傳遞接口MPI(Message Passing Interface)。一般由服務節點來控制整個集群。服務節點是集群的控制台和對外的網關。在規模比較大的Beowulf集群中可以有多個服務節點,例如專門用集群中的一個節點作為控制台或統計整個集群的運行狀態。通常,除服務節點外,Beowulf集群中的其他節點都是啞成員,即它們不與外界交互。這些成員節點由服務節點來管理,執行服務節點分配的任務。
Beowulf集群中的成員節點以及內部連接是集群專用的。從這一點來看,Beowulf更像是一台完整的機器,而不是一個由許多計算機組成的松散的群體。集群下的大多數節點沒有鍵盤、顯示器等,只是通過遠程登錄來訪問控制它們。就像CPU和內存可以方便地安裝到主板上一樣,Beowulf的節點作為內置的模塊插入Beowulf集群中。Beowulf集群中的節點之間的連接(通常是高速網絡,比如FastEthernet、ATM、Myrinet等)也是僅供節點間使用,它與集群與外界連接的普通網絡相隔離。這些特點使得Beowulf集群中各節點的負載均衡且節點之間的信賴關系變得更容易處理,因為它們不受外界的影響。同時,節點之間的通信也會更高效。Beowulf並不是一個軟件包、一種新的網絡拓撲結構或者內核技術,而是一種基於Linux操作系統的機器來構建並行虛擬機的思想。盡管有很多軟件(例如:內核的修改,PVM和MPI並行運算庫或者管理工具)可以使Beowulf體系結構更快、更容易管理和使用,但仍然可以只使用Linux來建造一個自身的Beowulf集群。一個最簡單的Beowulf集群可以由兩台互相連接並且擁有一些信任關系(比如NFS和rsh權限)的Linux計算機組成。
3 Beowulf集群系統硬件配置和結構
我們采用9台CPU為PIV-1.5GHz、內存為512M、硬盤為40GB/7200RPM、配有雙網卡的普通PC機作為節點組成集群機,實現基於消息傳遞的分布式內存的並行計算機系統。采用CISCO2900XL系列交換機(24口/100M),將交換機設置為3個虛擬網段,其中的一個網段設置為信息接收網段(LAN1),另一個網段設置為信息發送網段(LAN2)。LAN1只負責接收來自節點計算機的消息,將接收到的消息發送到LAN2的各個端口,LAN2將消息發送到相應的節點計算機,以使各節點計算機的兩個網卡分別進行消息的發送和接收,提高消息傳遞的速度。交換機的第3個網段用於將系統與局域網連接,從而實現遠程登陸服務等功能。
4 Beowulf集群系統Linux操作系統以及並行編程
環境的安裝
在本系統中,我們采用的操作系統是RedHat 7.1 (內核2.4.2-2smp)的Linux系統。並行編程環境采用基於消息傳遞接口(MPI) 的局域多計算機(Local Area Multi-computer,LAM),它是由Ohio超級計算機中心開發的,適用於異構Unix機群的MPI編程環境和開發系統。目前我們所安裝的LAM版本是6.5.2版。同時還安裝了Fortran 90開發平台。在RedHat7.1系統安裝結束以後,還安裝了f2c(Fortran-to-C)軟件包以及一些必要的服務軟件。由於每個節點有兩塊網卡分別擔任消息傳遞和接收的工作,並且兩塊網卡共用一個IP地址,為了實現這樣的功能,必須添加一個虛擬的網絡設備,將兩塊網卡綁定到這個虛擬的網絡設備上。在外界看來,每個節點只有1個IP地址和1塊網卡。在RedHat 7.1可以正常運行以後,必須啟動如下的系統服務:rlogin、rsh、nfs、ftp、telnet等。其中的rlogin和rsh服務只需要在8個計算節點上配置。出於安全方面的考慮,RedHat 7.1在默認的系統設置下,是不提供rlogin和rsh服務的,用戶必須手工設置必要的文件和參數,實現rlogin和rsh服務。相應的nfs(網絡文件系統)必須在服務節點和計算節點上同時配置。在所有的系統服務配置成功後,就可以安裝LAM6.5.2了,這個軟件包是免費的,可以到HTTP://WWW.LAM-MPI.ORG 下載最新的版本,安裝過程可以按照軟件包自帶的安裝說明進行安裝。安裝和配置結束以後,可以在Linux提示符下運行recon -v,來測試LAM是否成功安裝。
5 MPI簡介
一般並行計算機系統有兩個基本的體系結構:分布存儲和共享存儲。基於分布存儲的並行計算機的每個節點都有各自的本地存儲器,同時也能通過高速網絡接口等方式訪問其他節點的存儲器。各節點通過消息傳遞來進行數據交換。而基於共享存儲的並行機系統則是多個節點通過高速總線訪問一個全局的存儲器空間。這種方式由於總線帶寬的限制,一般將處理器個數限制在2~16個之間。最新的並行計算機體系結構使用分布存儲和共享存儲混合的方式,即每個節點都是由2~16個基於共享存儲的處理器組成,再由多個這樣的節點通過高速的通信結構構成分布存儲的並行計算機系統。MPI是由MPI論壇組織開發的適用於基於分布內存的並行計算機系統的消息傳遞模型。它提供了一個實際可用的、可移植的、高效的和靈活的消息傳遞接口標准。MPI以語言獨立的形式來定義這個接口庫。並提供了與C、Fortran和Java語言的綁定。這個定義不包含任何專用於某個特別的制造商、操作系統或硬件的特性。由於這個原因,MPI在並行計算界被廣泛地接受。其標准已由原來的MPI-1 發展到目前的MPI-2。MPI-1標准規定了如下的規范:(1) Fortran77和C分別調用MPI子程序(函數)的命名、調用順序以及返回值的規則,所有的MPI實現都必須遵循這些規則。從而保證遵循這些標准的MPI程序可以在任何平台上的可移植性;(2) 具體的MPI庫實現由硬件供應商提供,從而開發出適合各供應商硬件的最優版本。
MPI-2規范對MPI-1進行了如下的擴展:動態進程;單邊通信;非阻塞群集通信模式和通信子間群集通信模式;對可擴展的I/O的支持,叫作MPI-IO。在MPI-1中,I/O問題全部忽略。 MPI-1只定義對Fortran 77和C語言的綁定, MPI-2將語言綁定擴展到Fortran 90和C++;對實時處理的支持;擴展了MPI-1的外部接口,以便使環境工具的開發者更易於訪問MPI 對象。這將有助於開發剖析(profiling) 、監視(monitoring)和調試(debugging)工具。目前已經有一些MPI實現包括了MPI-2規范中的某些部分,但還沒有完全支持MPI-2規范的MPI實現。
6 MPI編程簡介
(1) MPI程序構成 一個標准的MPI程序由如下部分組成: 1) 頭文件 對於C程序,必須包含mpi.h頭文件,而對於Fortran程序,則應包含mpif.h。 2) MPI命名約定 為了避免與語言的命名沖突,約定所有的MPI實體(包括例程、常數和類型等)都以MPI_開頭。 3) MPI例程和返回值 所有MPI例程(函數或子程序)在C或Fortran調用中都返回一個整型值,用以確定MPI調用的退出狀態。 4) MPI句柄 MPI定義了自己用於通信的數據結構,必須通過句柄引用這些數據結構,這些句柄由各個MPI調用返回,並可能再次用於其他的MPI調用。在C語言中,句柄是指向特定的數據類型的指針(由C中的typedef機制創建),而在Fortran語言中,句柄則是一個整型數,例如MPI_COMM_WORLD在C語言中,是一個MPI_Comm類型(一個代表所有處理器集合的通信子)的一個對象,而在Fortran中,它是一個整型數。 5) MPI數據類型 參考C和Fortran中的基本數據類型,MPI提供了自己的參考數據類型,這些MPI數據類型主要用於MPI調用中的參數。 6) MPI初始化和結束 任何MPI程序在調用MPI例程之前,都必須首先調用MPI初始化函數,從而初始化MPI環境,這個初始化例程在C程序中名為: int MPI_Init(&argc, &argv) 而在Fortran中,則為: MPI_INIT(INT IERR) 所有的MPI調用結束以後,必須調用MPI_FINALIZE例程,用於清理所有的MPI數據結構,取消所有沒有完成的MPI操作;所有的處理器都必須調用此例程,如果任何一個處理器沒有完成此調用,程序將處於掛起等待狀態。在C和Fortran 中,調用的方式分別為: C: int MPI_Finalize(); Fortran: call MPI_FINALIZE(INTEGER IERR) 7) MPI通信子(Communicators) MPI通信子是一個代表一組能夠互相進行信息交換的處理器的句柄。每個通信子有各自的名稱,每個通信子必須允許send和receive調用進行通信,同時只有在同一個通信子內的處理器才能夠通信。 8) 獲得通信子信息:(處理器)次序和(通信子)大小。處理器通過調用MPI_COMM_RANK來確定其在通信子中的次序。處理器的次序定義有如下規則:通信子中的次序是從0開始的連續整數;一個處理器在不同的通信子中可以有不同的次序。 在C程序中,函數調用形式為 int MPI_Comm_rank(MPI_Comm comm., int *rank); 其中comm是MPI_Comm類型,代表一個通信子,在Fortran中,函數形式為: MPI_COMM_RANK(COMM,RANK,IERR) 使用MPI_COMM_SIZE可以獲得任何通信子中所包含的處理器個數。 C:int MPI_Comm_size(MPI_Comm comm., int *size) Fortran:MPI_COMM_SIZE(COMM,RANK,SIZE) (2) MPI程序實例(以C語言為例) #include <stdio.h> #include <mpi.h> void main(int argc, char *argv[] { int myrank, size; //Initialize MPI MPI_Init(&argc, &argv); //Get my rank MPI_Comm_rank(MPI_COMM_WORLD, &myrank); //Get the total number of processor MPI_Comm_size(MPI_COMM_WORLD, &size); Printf("Processor %d of %d: Hello World!\n",myrank,size); //Terminate MPI MPI_Finalize(); }
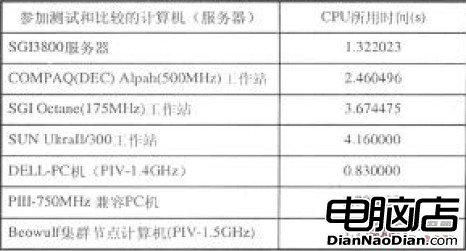
(2) Beowulf集群與其它並行計算機(集群)性能比較:
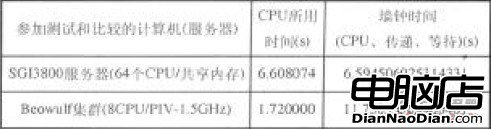
表2為Beowulf集群與SGI3800服務器的部分測試數據(均使用8個節點),根據測試結果,在程序執行時間以及牆鐘時間(包括CPU、傳遞、等待等)等指標上,Beowulf集群與其它同類並行計算機(集群)的性能相當。
表2 並行計算性能比較
8 結語
基於Linux系統的Beowulf集群系統在等離子體物理實驗以及數值模擬等方面的應用,極大地提高了運算效率和處理能力,為等離子體物理研究領域提供了一個非常有效的高性價比的工具。